分類:AI人工智慧學習
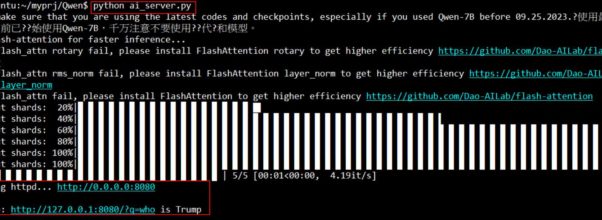
Current large language models all have accompanying HTTP APIs, such as the one mentioned in this art
目前的語言大模型都有搭配的 http API, 像在這篇裡提到的 Langchat-chatcat 的 API。使用上算不上複雜,但想要使用時要下的參數好像就有點多。其實要搭建自己的 LLM API,
This article refers to the youtube video。 Using Stable Diffusion (referred to as SD) has always been
本文參考內容,為 Youtube 上的這個影片。 使用 stable diffusion (以下稱 SD) 一直是隨便玩玩而已,可以說是邊玩邊學一點。因為至今還是沒辦法搞出什麼生產力,所以只能繼續的學
“Stable Diffusion” has recently released the SDXL 1.0 version (hereinafter referred to a
Stable Diffusion 最近出了 SDXL 1.0 版本 (以下簡稱SD),應該是畫質更好,提示詞更簡單。不過其實 Stable Diffusion 我也沒什麼在用,就是偶爾玩一下而已。最近
Recently started understanding machine learning and often need to reinstall the environment, but som
After using Azure TTS in the previous article (link), I will study the reverse technology: speech re
在前一篇利用 Azure TTS 來進行TTS後, 接著就研究反向的技術, 語音轉文字。微軟當然也有這項 API, 但語音識別有 Facebook 推出的 SeamlessM4T 模型可以做,而且效果
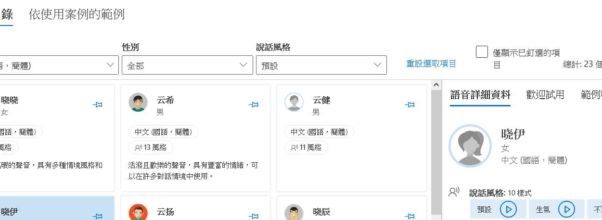
A while ago, I searched for a long time to find a free Chinese-to-speech language model with no resu