This article refers to the youtube video。
Using Stable Diffusion (referred to as SD) has always been just for fun and learning a little bit along the way. Since it has not been able to generate any productivity so far, one can only continue to learn, keep up with the times, cultivate some knowledge, and not fall too far behind when the time comes.
In the use of SD, we initially focused on prompts, but later found that the model had a greater impact. A good model can produce beautiful pictures at will, but these do not count as knowledge either. One feature of picture generation is to generate multiple characters with different descriptions, so we searched for it and found the video mentioned earlier.
But the extension it uses are not quite perfect; the image gets wider and more people appear than specified, so this is also not the final solution. It’s just for learning records and to fool some clicks.
Stable Diffusion generates multiple characters
Install plugin
To generate multiple characters in stable diffusion, install 2 plugins: Latent Couple extension (two shot diffusion port) and Composable LoRA. The installation method is to go to the extension page after starting stable diffusion, and specify the URLs of these two plugins to proceed with the installation.
- https://github.com/opparco/stable-diffusion-webui-composable-lora
- https://github.com/opparco/stable-diffusion-webui-two-shot
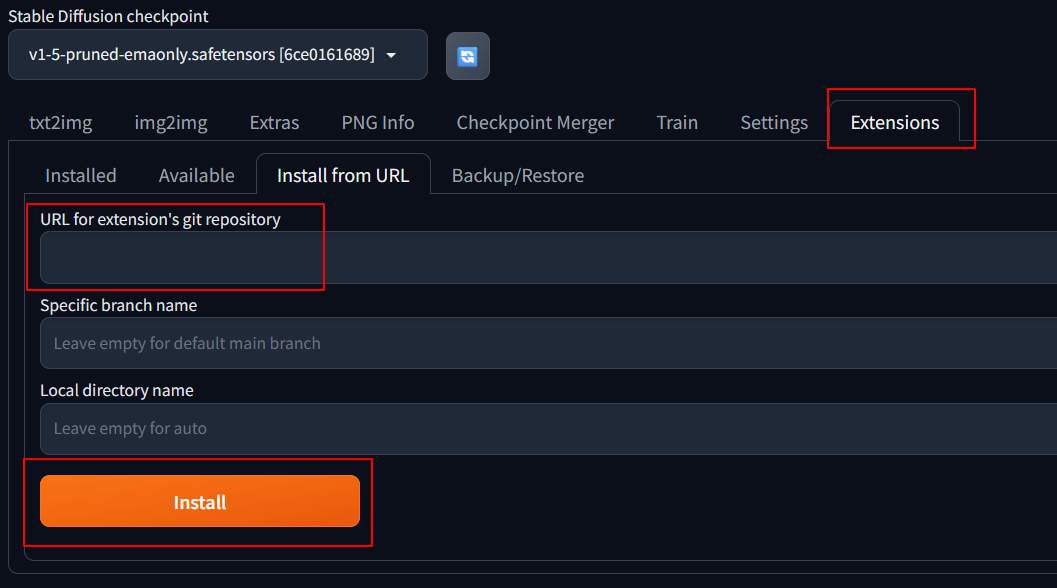
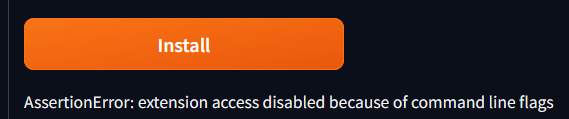
If you encounter installation failures, you can use the “–enable-insecure-extension-access” flag.
|
1 |
./webui.sh --listen --enable-insecure-extension-access |
After installation, restart the SD card.
View plugin
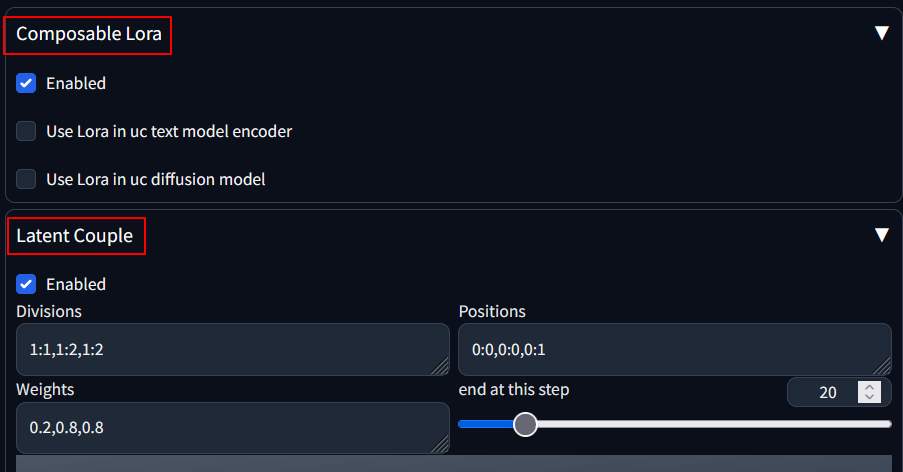
After restarting, at the bottom of the txt2img page, you can see two settings: “Composable Lora” and “Latent Couple.” Select both items as enabled.
Issue the prompt “two girls” with the model “v1-5-pruned-emaonly.safetensors” and use the seed 643249611 to generate an image, which should result in the picture below.

Then, use the following prompts to generate pictures
|
1 2 3 |
two girl, AND two girl, silver hair AND two girl, black hair |
As you can see in the picture description, both silver-haired and black-haired girls appear.

Generate 3-person image
The example above is an example for two people, with the following setting of their latent coupling:
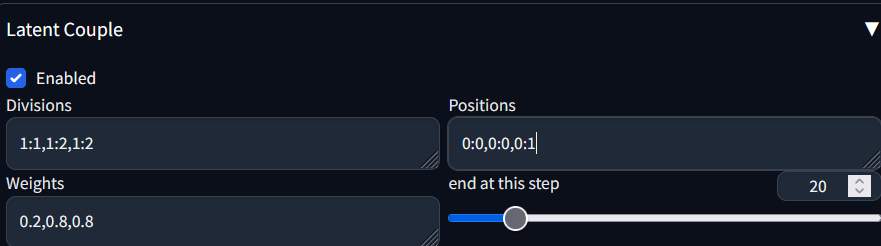
To generate 3 people, change the setting.
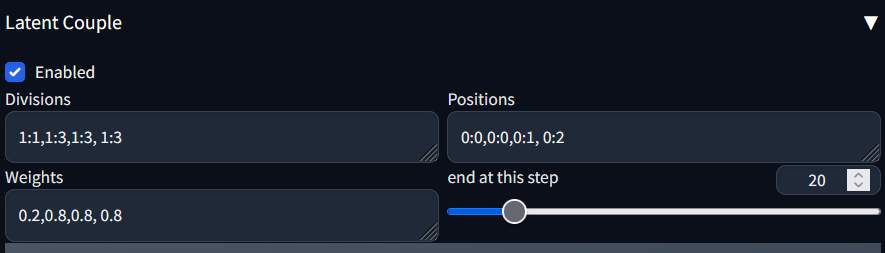
The prompt used are
|
1 2 3 4 |
3 girl, AND 3 girl, silver hair AND 3 girl, black hair AND 3 girl , red hair |
The picture generated are

Although it’s a bit scary, it’s still consistent with the description. Using different models can generate more beautiful graphs. Using “anything-v3-full.safetensors” can produce the following graph:

The meaning of parameters can be inferred from comparison.
- Division: The first one is 1:1, and the rest are 1:n, depending on how many characters there are, with n being the number of shares.
- Positions: The first one is 0:0, and the others are 0:1, 0:2… depending on how many people there are.
- Weight: The first one is 0.2, and the rest can be set to 0.8.
Uncertainty
The above parameters seem to be normal in the case of 1024×512, but when I generate an image of 1920×1080, it becomes as follows:

Three people were supposed to come, but six of them showed up instead.
Conclusion
SD is actually quite good, with a large range of customizability (unstable). Compared to Dalle3, although it produces unexpected results, it also represents a larger range of adjustability. In terms of AICG, there still seems to be plenty of room for optimization, and I can already feel the need for a prompt programming language to do this job. Humans’ vague mode of expression is so unclear that even AI doesn’t understand it!”

{kind=link}