本文參考內容,為 Youtube 上的這個影片。
使用 stable diffusion (以下稱 SD) 一直是隨便玩玩而已,可以說是邊玩邊學一點。因為至今還是沒辦法搞出什麼生產力,所以只能繼續的學習,跟著時代的進步,培養一些知識,哪天時候到了才不會落後太多。
SD 的使用上,一開始專注於提示詞,後來發現模型影響更大。模型好,隨便出圖都很漂亮,但這些也算不上什麼知識。其中出圖的一點就是想要產生多個人物,而且有各別的描述,所以就找了一下,就找到前面提的影片了。
但它所使用的插件 (extensions) 用起來還是不那麼完美,畫面變寬,出現比指定的人數還要多了,所以也算不算最終方案。就當學習紀錄,騙騙點擊了。
Stable Diffusion 產生多人物
安裝插件
在 stable diffusion 要產生多人物,要安裝2個插件。Latent Couple extension (two shot diffusion port) 與 Composable LoRA。安裝方式是在啟動stable diffusion 後,到 extension 頁面分別指定這個2個插件的網址以進行安裝
- https://github.com/opparco/stable-diffusion-webui-composable-lora
- https://github.com/opparco/stable-diffusion-webui-two-shot
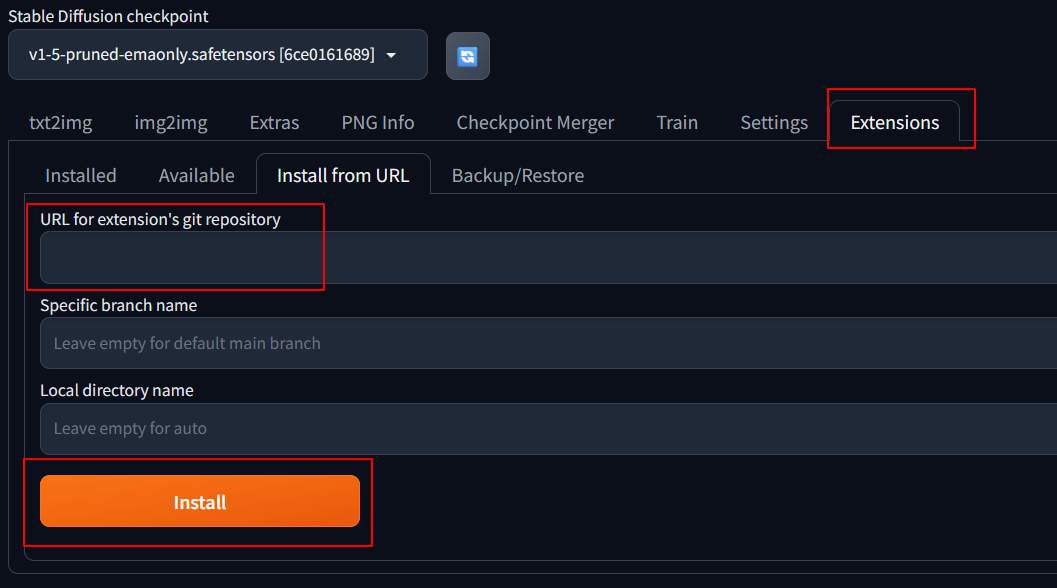
若出現安裝失敗,可以打開 “–enable-insecure-extension-access” 的這個 flag
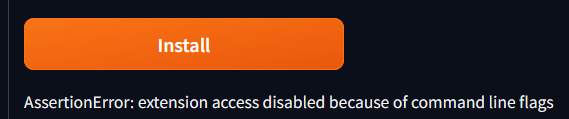
|
1 |
./webui.sh --listen --enable-insecure-extension-access |
安裝完畢後,重啟 SD
檢視插件
重啟後,在 txt2img 頁面的最下方,可以看到 Composable Lora, Latent Couple 兩個設定。將2個項目,都勾選 enabled
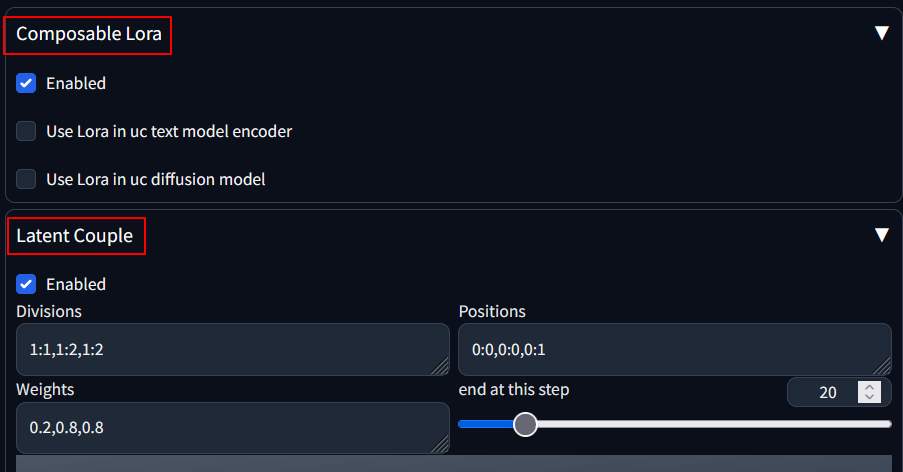
這時以模型 v1-5-pruned-emaonly.safetensors 下達提示詞 two girl, 並以 seed 643249611 來產生圖片,應該可以看到下面這個圖片。

接著以如下提示詞產生圖片
|
1 2 3 |
two girl, AND two girl, silver hair AND two girl, black hair |
就可看到如圖描述的銀髮與黑髮女孩出現

產生3人圖片
上面的例子是2人的例子,其 latent couple 的設定如下
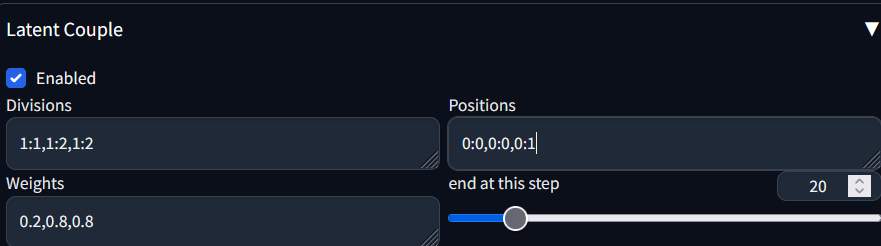
若要產生3人的話,將其設定改為
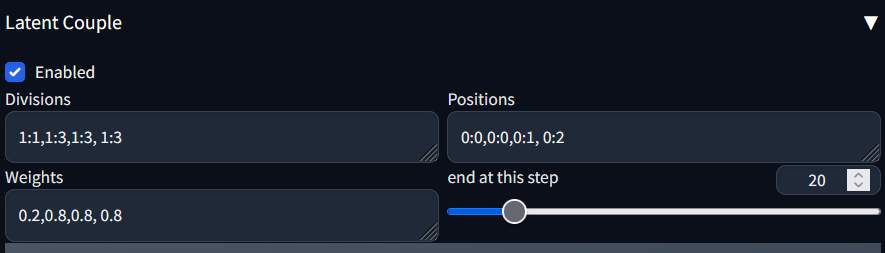
而提示詞改為
|
1 2 3 4 |
3 girl, AND 3 girl, silver hair AND 3 girl, black hair AND 3 girl , red hair |
就可以產生圖片如下

雖然有點可怕,但還算是符合描述了。用不同的模型,可以產生比較漂亮的圖。用 “anything-v3-full.safetensors” 可以產生如下的圖

參數上的意義,可以從比較得出
- Division: 第1個是1:1, 後面就是1:n, 看有幾個人物, n就是多少,而且要有幾份
- Positions: 第一個是0:0, 後面就是0:1, 0:2…看有幾個人
- Weight: 第一個是0.2, 後面都用0.8就可以了。
不確定性
上面的參數,在 1024×512狀況都還算正常,但當我產生了一張 1920×1080 的圖後,就變成如下

說好的3個人,變成了6個人~~~
結語
SD 其實算的上是不錯了,可自訂的範圍很大(不穩定),比較 Dalle3 雖然有意料外的結果,也代表著更大的可調範圍。在 AICG 這一塊,感覺還有很大的優化空間,我已經隱約感覺到需要一個提示詞程式語言來做這項工作了。人類這種語焉不詳的模式,連 AI 都搞不懂啊~~~

{kind=link}