本篇要介紹的是一個有趣的功能「AI繪圖」,教學文章參考自「AI繪圖:Windows安裝Stable Diffusion WebUI教學」。
原本的教學文章是在 Windows 上的,由於我的環境是 Linux ,中間一部份很基本的段落,就不詳述了。這篇是比較偏應用,訓練的部份尚未研究。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 |
conda create -n aidraw python=3.9 |
下載模型
根據教學文章,要下載2個模型。
- 臉部修復模型: GFPGAN, 請到這裡 ,下載 GFPGANv1.4.pth (332M)
- 繪圖用的模型: 可以裝多種:
- 真人風格: Stable diffusion 的, 可於這裡 找到各個版本的,1.4 版的檔案連結 sd-v1-4.ckpt(4.3G)
- 漫畫風: Anything v3.0, 至 這裡 下載 anything-v3-full.safetensors (7.7G)
- 漫畫風2: waifu, 至這下載 , 下載 wd-v1-3-full.ckpt (7.7G)
下載 Stable Difussion Web ui
這邊要下載 Stable Difussion 的 WEB UI 專案,以下列指令下載程式
|
1 2 3 4 5 |
cd projects git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git cd stable-diffusion-webui echo "conda activate aidraw" > env.sh source ./env.sh |
專案下載後,將檔案依下列方式放置
- 臉部修復模型: GFPGANv1.4.pth, 放到 stable-diffusion-webui 目錄下。
- 繪圖用的模型: 放置於 stable-diffusion-webui/models/Stable-diffusion。 將 anything-v3-full.safetensors 或 wd-v-1-3-full.ckpt 移到該處 。
我的已經下載過了,所以只需建立link
|
1 2 3 4 5 |
ln -s /cache/common/models/stable-diffusion/GFPGANv1.4.pth ln -s /cache/common/models/stable-diffusion/wd-v1-3-full.ckpt models/Stable-diffusion/ ln -s /cache/common/models/stable-diffusion/anything-v3-full.safetensors models/Stable-diffusion/ ln -s /cache/common/models/stable-diffusion/Chilloutmix-Ni.safetensors models/Stable-diffusion/ #請自 civita 下載 ln -s /cache/common/models/stable-diffusion/ulzzang.bin embeddings/ #請自 civita 下載 |
安裝套件
|
1 2 3 4 |
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c nvidia -y pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113 pip install tensorflow chardet xformers pip install transformers pandas jieba scikit-learn |
fastapi 問題修正
若碰到下列錯誤,可以用此方式修復。
|
1 |
RuntimeError: Cannot add middleware after an application has started |
參考這裡的討論,可以透過下列方式解決
|
1 2 3 4 |
# 進入 stable-diffusion-webui source ./venv/bin/activate pip install fastapi==0.90.1 deactivate |
啟動程式
最後執行, 其中的 –listen 是指定要在所有的 IP 上做服務,不然只會允許本機使用。
|
1 |
./webui.sh --listen |
啟動後還做了很多事,包含安裝套件、clone其它專案。完畢後就會啟動服務。
然後以瀏覽器打開伺服器網址的 7860 port ,就可以始用該服務了。
|
1 |
http://YOUR_SERVER_IP:7860 |
就可以使用該服務了。
簡單範例
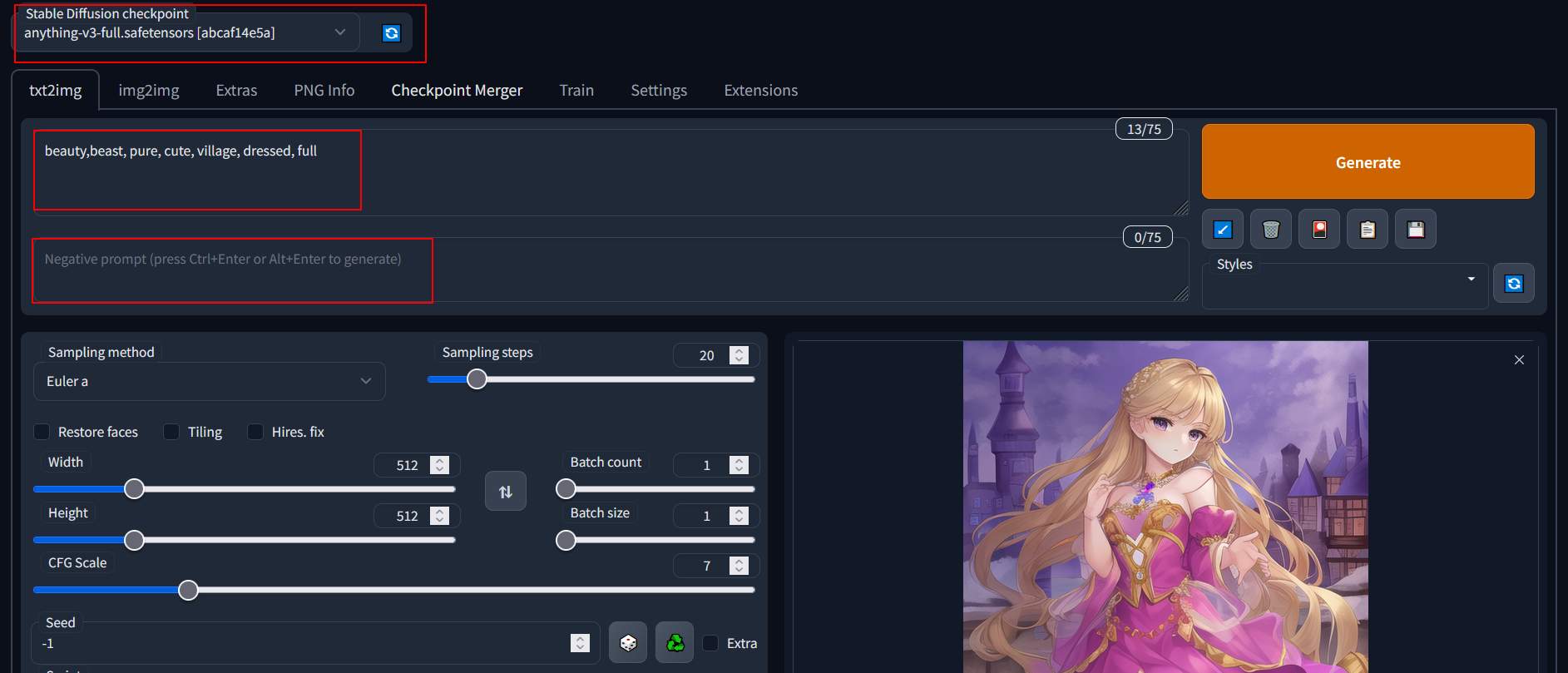
Stable-Diffusion 範例
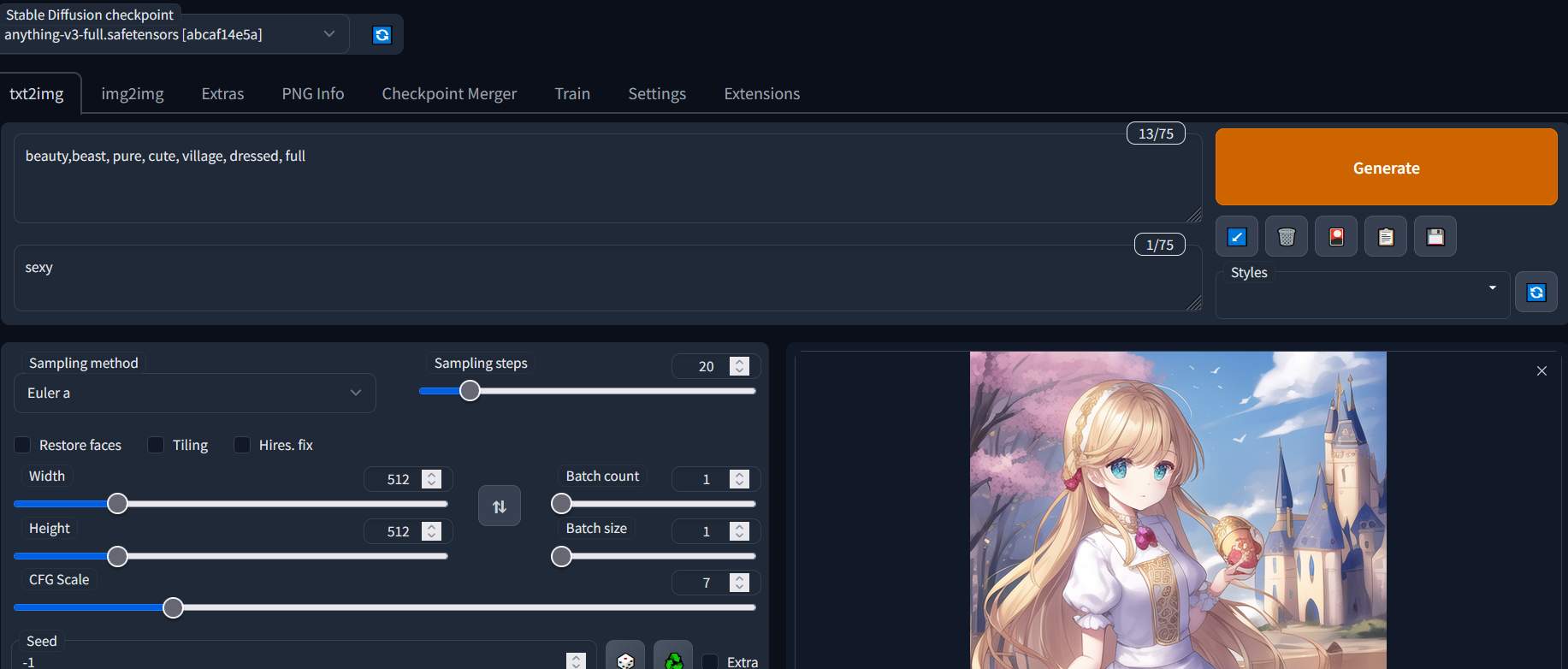
「純潔」一點的圖
主要有3個地方,其它應該隨便試就知道了
- 最上面的紅框,是選擇要用的模型,應該會包含剛下載的 anything 與 wd。
- 第2個框是提示詞,一些跟想產生的圖相關的單字。
- 第三個是避免的性質描述詞,第2個圖就是加入避免”sexy”的特性,產生的圖就比較純潔了。
相關連結
網路上也有很多厲害的人,提供可以產生各式各樣的擬真圖片,我個人很推荐 JoeMultimedia 的Youtube頻道。以下是參考他這個影片製做而產生出來的圖。下面一樣記錄我自己的操作指令
|
1 2 |
ln -s /cache/common/models/stable-diffusion/ulzzang.bin embeddings/ ln -s /cache/common/models/stable-diffusion/Chilloutmix-Ni.safetensors models/Stable-diffusion/ |
這邊可以看到其 prompt 和 negative 填了一大堆,這也是所謂的「咒語」。真的蠻貼切的,像變魔術樣。
|
1 |
RAW photo, delicate, best quality, (intricate details:1.3), hyper detail, finely detailed, colorful, 1girl, solo, 8k uhd, film grain, (studio lighting:1.2), (Fujifilm XT3), (photorealistic:1.3), (detailed skin:1.2),1 girl,cute, solo,beautiful detailed sky,detailed cafe,dating,(nose blush),(smile:1.15),(closed mouth), middle breasts,beautiful detailed eyes, daylight, wet, rain, (short hair:1.2),floating hair NovaFrogStyle, full body,turtleneck,ribbed sweater,see-through,wet clothes |
|
1 |
paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (outdoor:1.6), manboobs, backlight,(ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.331), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (more than 2 nipples:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), bad hands, missing fingers, extra digit, (futa:1.1), bad body, NG_DeepNegative_V1_75T,pubic hair, glans |
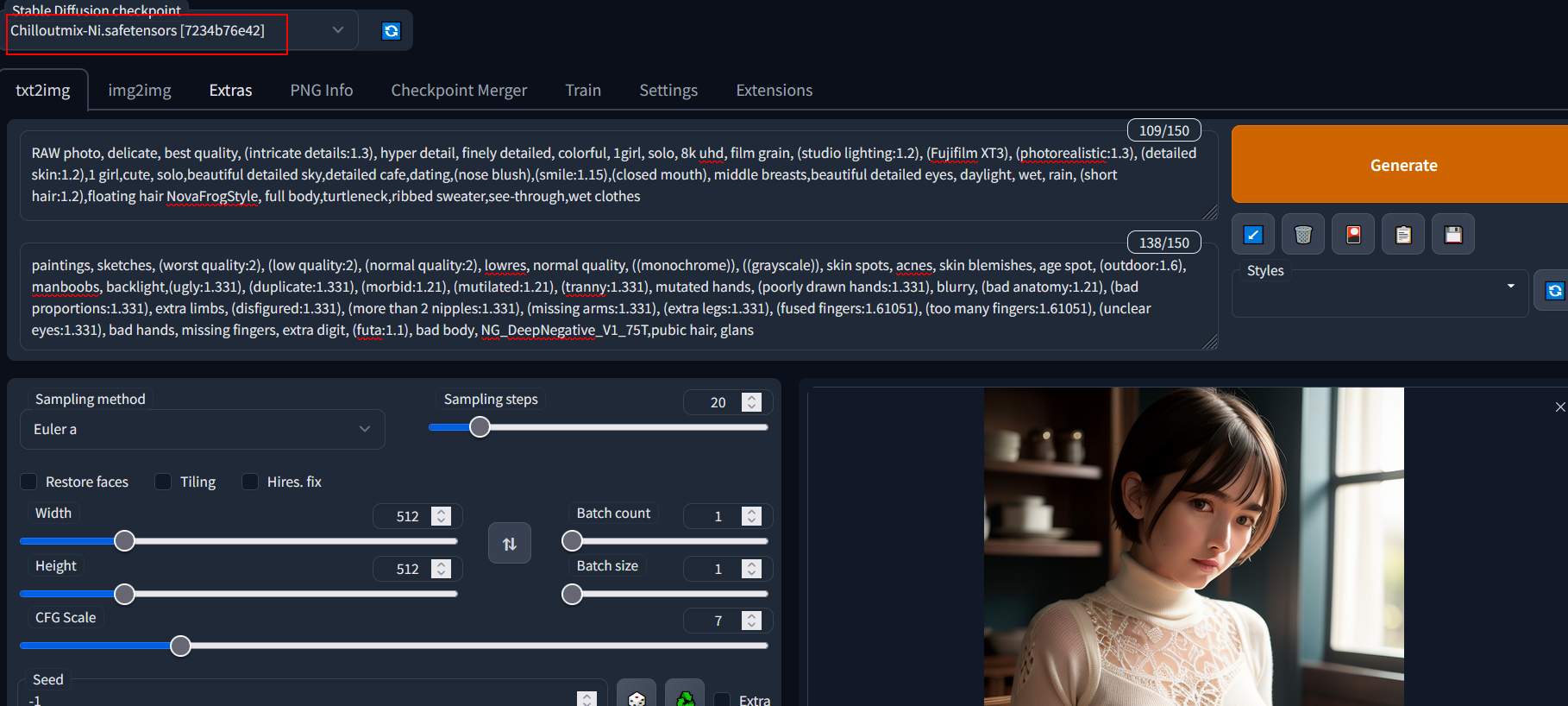
超逼真人相

一次產生5張看飽一點
要產生色色圖的話,稍微改一下 prompt 就可以了
|
1 |
RAW photo, delicate, best quality, (intricate details:1.3), hyper detail, finely detailed, colorful, 1girl, solo, 8k uhd, film grain, (studio lighting:1.2), (Fujifilm XT3), (photorealistic:1.3), (detailed skin:1.2),1 girl,cute, solo,beautiful detailed sky,detailed cafe,dating,(nose blush),(smile:1.15),(closed mouth), huge breasts,beautiful detailed eyes, daylight, wet, rain, (short hair:1.2),floating hair NovaFrogStyle, whole body, naked, legs |


{kind=link}