Stable Diffusion 最近出了 SDXL 1.0 版本 (以下簡稱SD),應該是畫質更好,提示詞更簡單。不過其實 Stable Diffusion 我也沒什麼在用,就是偶爾玩一下而已。最近想要產生一些內容農場的文章,於是研究了一下語言大模型、TTS,現在就缺這自動產生圖片了。所以就研究了一下 SD, 但發現提示詞不是那個容易,比較 Dallee-3 笨了很多。
但 SD 其實也不是不好,就是要多調參數和提示詞。所以就先從比較有趣的 Lora 微調模型,開始來研究一下。
本文相對而言,還蠻複雜的,是用 Docker 來架設 SD,和微調環境。由於這種目的是少用變化大,所以決定用 Docker 來進行。本文還是用最受歡迎的川普照片來做為範例,若川建國大大有不滿意,隨時跟我聯絡喔~~~
建立 Docker 容器
用下面命令來建立 docker 容器
|
1 |
docker run -it --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -p 7860:7860 -p 7861:7861 -p 2222:22 nvcr.io/nvidia/pytorch:22.12-py3 |
安裝套件
|
1 2 |
apt-get update apt install build-essential cmake libgl1-mesa-glx python3-tk openssh-server |
編輯 /etc/ssh/sshd_config,將下面項目改成如下
- PermitRootLogin yes
- UsePAM no
然後用 passwd 設定密碼, 改成一個非空的值。
執行下列命令,在容器啟動時,啟用ssh server
|
1 |
echo "/etc/init.d/ssh restart" >> /root/.bashrc |
亦可用下列面命令,立刻啟動 ssh server
|
1 |
/etc/init.d/ssh restart |
安裝 miniconda
因為會同時跑2個專案,所以下載 miniconda 進行安裝。安裝流程與 anaconda 相同,這邊不再贅述。
安裝 Stable Diffusion
使用ssh 登入,先創建 conda 環境
|
1 2 |
conda create -n sd python=3.10.8 conda activate sd |
接著下載專案
|
1 2 |
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui cd stable-diffusion-webui/ |
編輯 webui.sh, 將下列項目設定如下
- use_venv=0
- can_run_as_root=1
接著開始執行 webui.sh,程式自行安裝所需套件
|
1 |
./webui.sh --listen --port 7860 |
若中間有錯誤,可試著重裝 torch 來解決問題
|
1 2 |
pip uninstall torchvision torch pip install torchvision torch |
安裝 Kohya
使用ssh 登入另一個連線(重要! 避免環境衝途),先創建 conda 環境
|
1 2 |
conda create -n kohya python=3.10.8 conda activate kohya |
接著下載專案
|
1 2 3 4 5 |
git clone https://github.com/bmaltais/kohya_ss pip install scipy cd kohya_ss/ ./setup.sh ./gui.sh --listen 0.0.0.0 --server_port 7861 --headless |
同上執行時也可能出現錯誤,也是重安裝 torch. 有預到再試試看,沒遇到就可忽略。
|
1 2 |
pip uninstall torchvision torch pip install torchvision torch |
但在 koyha 啟動時,會檢查套件的版本,錯誤就會被重安裝,所以要改一下 requirements.txt,改成自己安裝的最新版本。
另外有時也會講 “accelerator” 沒設定,要你自己下 “accelerator config”做設定。執行該命令,最後面的精度選 fp16,其它照預設值即可。
檔案預處理與自動產生提示詞
將本文的範例檔案透過 ssh 複製到根目錄下,將其解壓縮。
接著用瀏覽器連到 SD 的網頁 http://IP:7860 來使進行自動檔案載切,與自動判定提示詞。
進入頁面後,選擇 Train –> Preprocessing Images, 依下面描述填入設定值
- Source directory: /root/raw/30_trump/
- Destination directory: /root/out/30_trump/
- Use BLIP for caption: 勾選
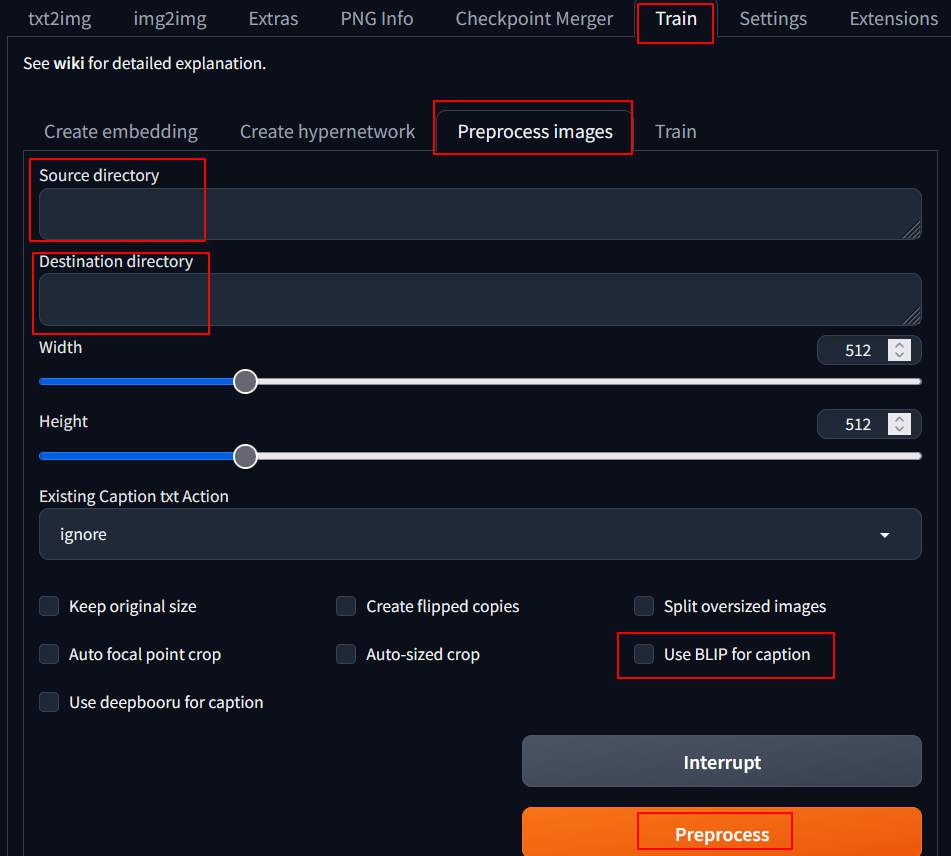
接著就可以選擇 Preprocess 來進行處理,會先開始下載其它模型 (應該是圖生文的),再進行處理。
處理完後,可以看到 /root/out/30_trump 裡面就會有一圖搭配一文的檔案。而同名文字檔, 就是該圖片的描述。接著將每一個文字檔最後面都加上 “, trumpboss” ,來將此字與圖片產生相關,往後用這個模型微調,就會套用該圖片的某些風格。範例裡面有一個 addtag.sh,可方便直接加入上面的 tag
|
1 2 3 |
cd /root/out chmod a+x addtag.sh find 30_trump/ -name "*.txt" -exec ./addtag.sh {} \; |
關於圖片提示詞的修改,我並沒有特別去研究,有興趣的可能要再自己找找。看影片不專業的印象,修改方向如下
- 想要該圖片風格可替換的部份,就不要在文字檔案描述
- 想要某特定項目不要替換的,就要在圖片裡描述。
Kohya 進行 Lora 訓練
打開瀏覽器 IP://7861 開啟正在運行 Kohya。設定參數如下:
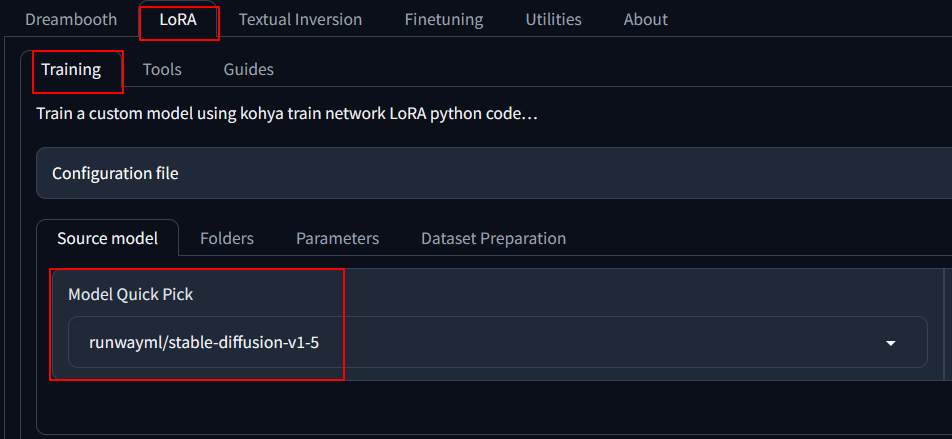
Lora –> Source Model –> Model Quick Pick, 設定為 runwayml/stable-diffusion-v1-5
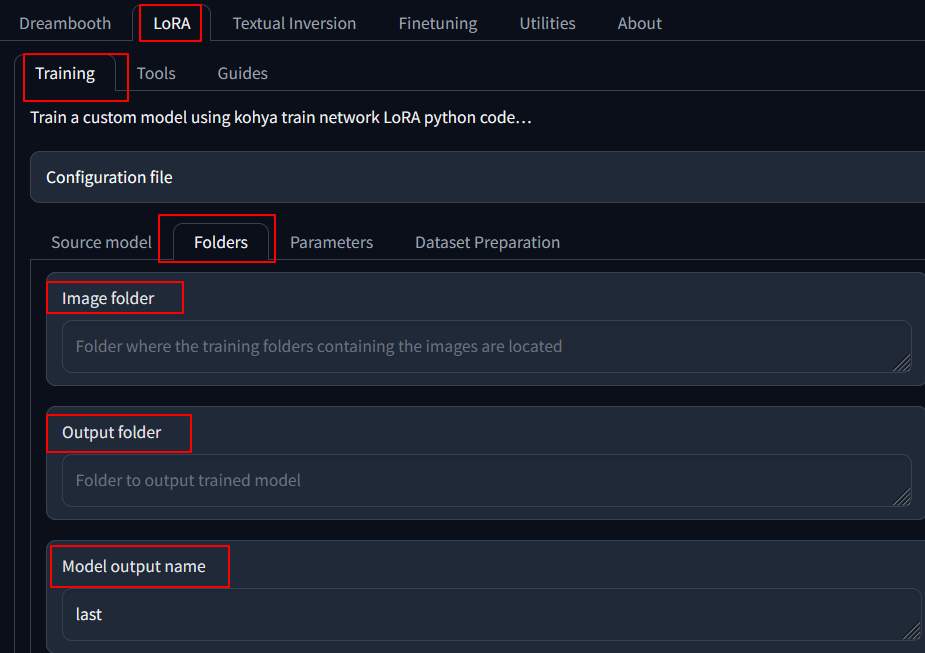
Lora –> Folders,
- Image Folder: /root/out
- output folder: /root/model
- Module output name: trump
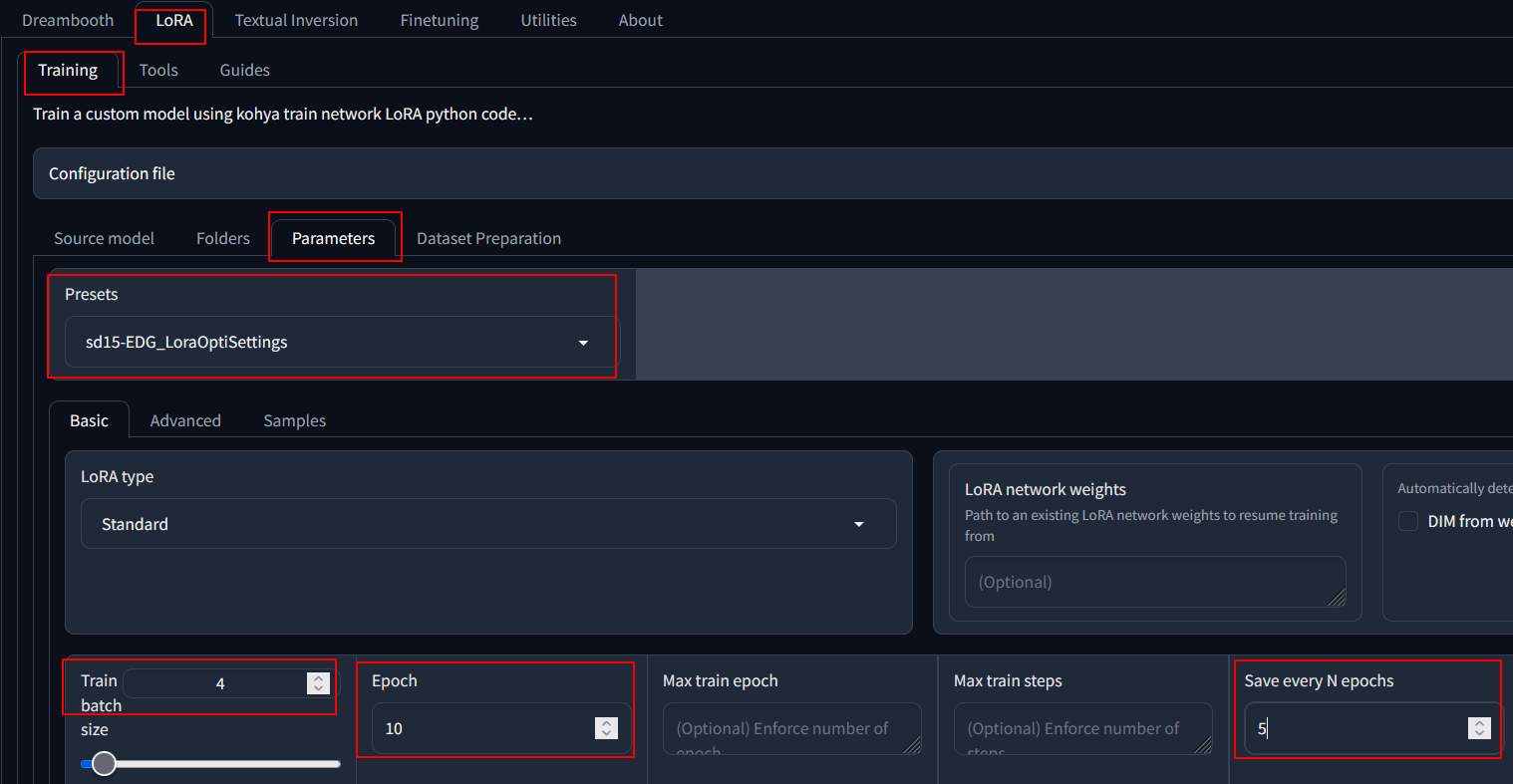
Lora –> Parameters
- Preset: sd15-EDG_LoraOptiSettings
- Train batch size: 4
- Epoch: 10
- save every n epoch: 5
接著就可以到最下面按下 “start trainning”,接著也會先下載模型,實際訓練接, 以4090訓練的話,大概是 5 分鐘可完成。
這邊要注意的是,若你最重要套用的模型的版本要和Lora訓練時的版本是一樣的,這麼都是使用 1.5 當範例。
訓練完成後將檔案複製到 SD 的 Lora 下
|
1 |
cp /root/model/trump.safetensors /root/stable-diffusion-webui/models/Lora/ |
目錄命名原則
在處理過後的圖檔目錄,是用 30_trump 來命令。具說30是一張圖片的要訓練的次數,覺得時間花太久,或不夠好,都可以調調看。
SD 套用 Lora 模型
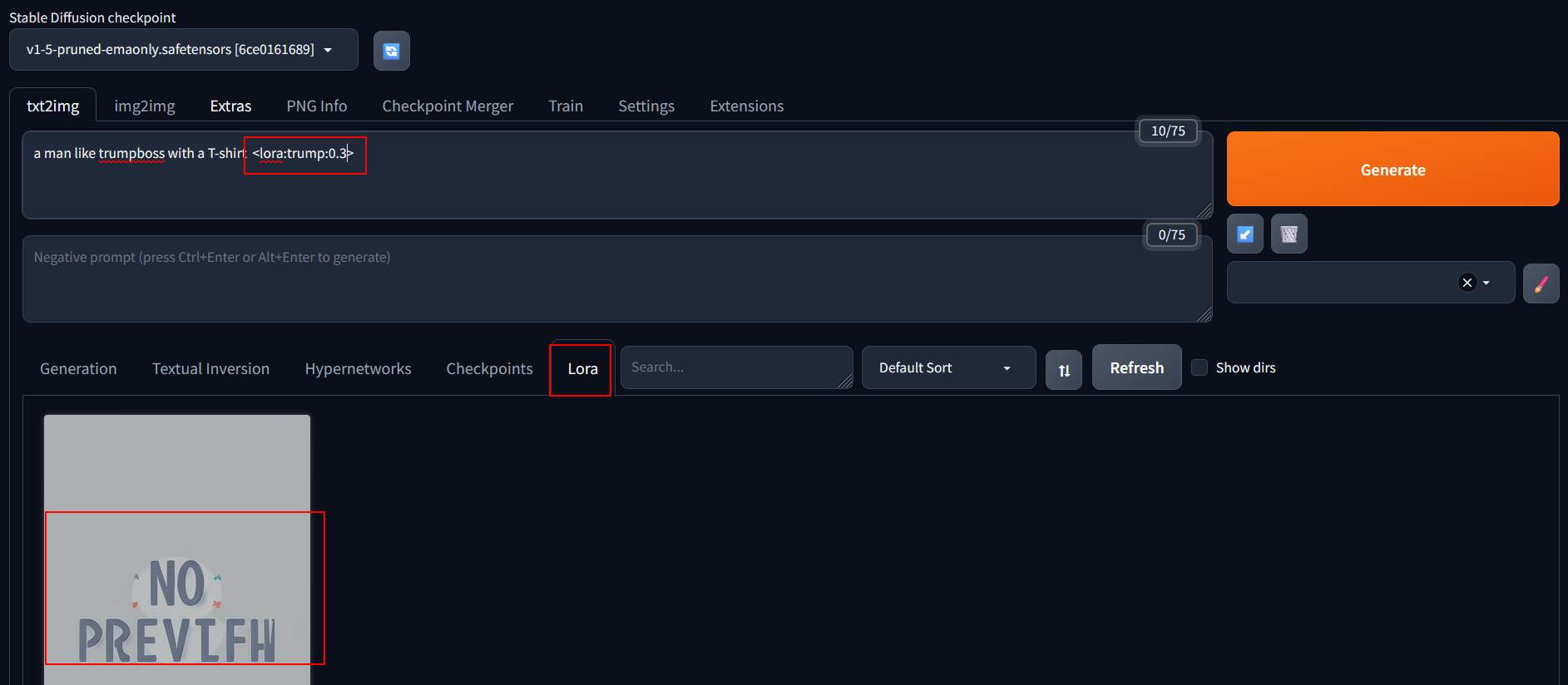
重新啟動 SD, 連入後在提示詞填入 「a man like trumpboss with a T-shirt <lora:trump:0.5>」。在Lora Tab 上按下訓練好的模型,就會自動帶入參數。此時再調整權重,試試看不同的效果。

結語
整個過程不算太難,但由於步驟太多顯得有點複雜,另外套件安裝常常也會發生錯誤。建議要長期使用的,安裝在 docker 內會比較省麻煩。Kohya 是比較容易出錯的部份,感覺每次安裝狀況都不太一樣 @@,希望往後有更方便的套件。
還有下面參考的連結裡面有一句話,真是一句話打醒夢中人「一个血的教训是:一个好的模型随便出的图,可能会比你费劲心血、测试修改上百遍的Prompt所输出的结果还要好」
參考連結
我所記錄的都很簡化,要瞭解更細節的,可參考更多的教學。第4個參考資料是個 40 分鐘的 Youtube 影片,比較全面,一步一步教學。
- Stable Diffusion — 訓練LoRA
- Stable Diffusion模型优化入门级介绍
- Stable Diffusion WebUI使用手冊(正體中文)|Ivon的部落格
- 【Stable Diffusion】LoRA炼丹 超详细教学·模型训练看这篇就够了


{kind=link}