A while ago, I searched for a long time to find a free Chinese-to-speech language model with no results. I had to learn how to use Microsoft’s text-to-speech service instead.
The Azure TTS service is highly regarded for its good performance, offering a wide range of languages and voices. Many YouTube voiceovers are created using it, and it provides a free quota of 5 million characters per month to use. Since there should be many tutorials online about registration, I will just provide my code here as a quick start.
Assuming the service has been applied for and a speech service has been set up, to enter the page that converts text to speech: search for “Azure TTS” on Google -> log in from the upper right corner -> select resources -> your speech service -> go to speech studio -> scroll down to find Text-to-Speech.
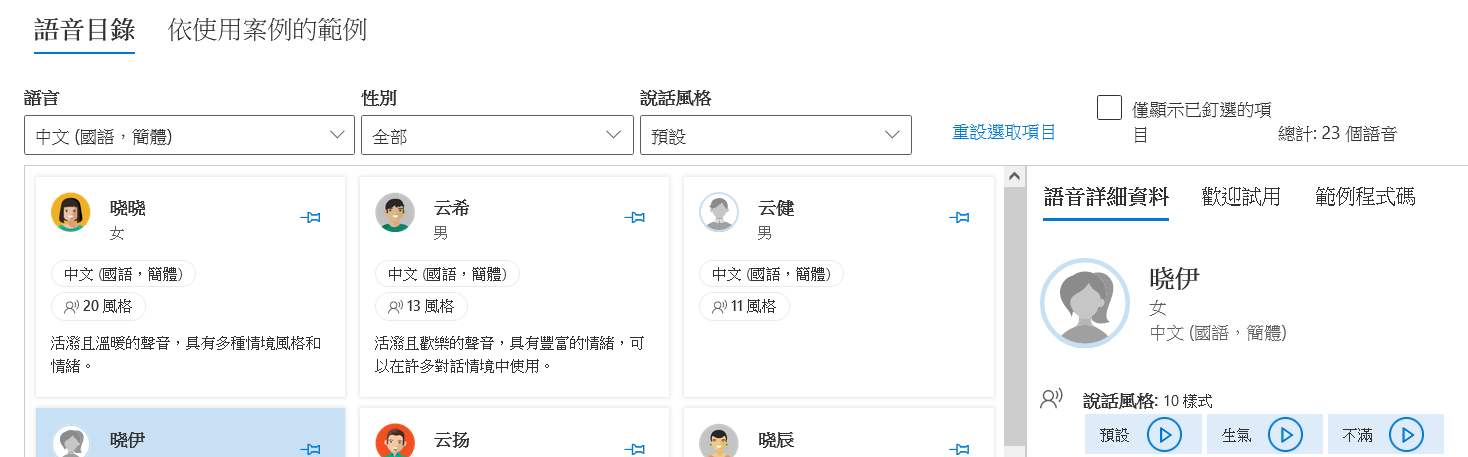
As shown in the picture, you can select different voices and listen to them, try them out, and use the code. The code part will automatically insert the name of the role and the style into the trial according to the voice you are trying. But I haven’t tried it yet, so I still don’t know how to insert the style into the program.
My Sample Code
To use Azure services, you need to install its SDK.
|
1 |
pip install azure-cognitiveservices-speech |
My sample code to run TTS.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import azure.cognitiveservices.speech as speechsdk speech_key = "YOU_API_KEY" service_region = "YOUR_REGIN" speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) speech_config.speech_synthesis_voice_name = "zh-CN-XiaoyanNeural" speech_config.set_speech_synthesis_output_format(speechsdk.SpeechSynthesisOutputFormat.Audio16Khz32KBitRateMonoMp3) text = "大家好,我想要去台北玩,請推荐試合的景點。" speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config) result = speech_synthesizer.speak_text_async(text).get() # Check result if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted: print("Speech synthesized for text [{}]".format(text)) stream = speechsdk.AudioDataStream(result) stream.save_to_wav_file("out.mp3") elif result.reason == speechsdk.ResultReason.Canceled: cancellation_details = result.cancellation_details print("Speech synthesis canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) |
L3~4: Input your key and region. The example from Azure will have it pre-filled for you. If you forget, you can refer directly to it.
L7: Specify the output format as mp3. If not specified, it will be read out directly.
L8: The text you want to do TTS
L15~16: save the result to MP3
Conclusion
Microsoft’s speech effect is indeed very good, even I am considering joining the ranks of YouTube content farms. It turns out that all the videos I watch every day are like this!

 Service){kind=link}