前一陣子苦尋免費中文轉語音的語言模型,無耐找了很久,全部都效果不彰。只好學一下怎麼用微軟的文字轉語音服務。
Azure 的 TTS 服務是有口碑的好效果,可選的語言和人聲很多,很多 youtube 上的配音都是用它轉出來的,每月有提供50萬字的免費額度可以使用。由於網路上應該有很多介紹注冊方面的東西,這裡就直接把我的程式碼給出來,當快速入門就好了。
假設已申請好服務,也建立了語音服務。要進到轉語音的網頁,就在 Google 上找 “Azure TTS” –> 右上角登入 –> 選擇資源 –> 你的語音服務 –> 前往 speech studio –> 往下找到文字轉語音
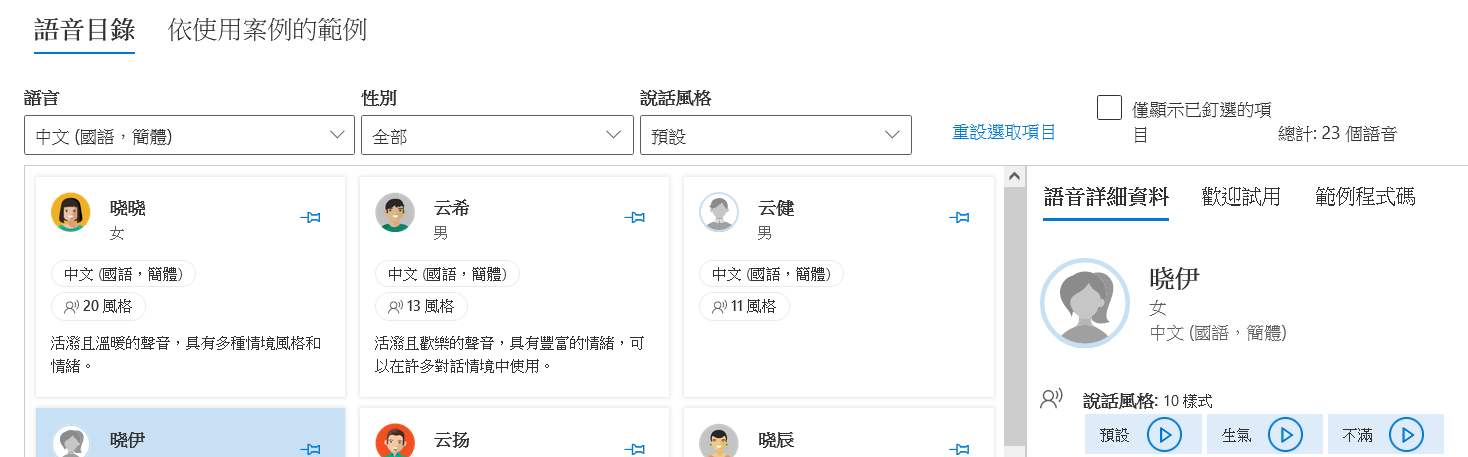
如同圖片所示,可以選不同的人聲,再進行試聽、試用和程式碼。程式碼的部份會根據你試用的人聲,自動代如角色的名稱,風格的方式在試用裡面有列表。但我沒試過,所以還不知道在程式裡怎麼代入風格。
範例程式碼
要使用 Azure 服務,要先裝其套件
|
1 |
pip install azure-cognitiveservices-speech |
完成後就可以用下列程式碼來產生語音 mp3
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import azure.cognitiveservices.speech as speechsdk speech_key = "YOU_API_KEY" service_region = "YOUR_REGIN" speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) speech_config.speech_synthesis_voice_name = "zh-CN-XiaoyanNeural" speech_config.set_speech_synthesis_output_format(speechsdk.SpeechSynthesisOutputFormat.Audio16Khz32KBitRateMonoMp3) text = "大家好,我想要去台北玩,請推荐試合的景點。" speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config) result = speech_synthesizer.speak_text_async(text).get() # Check result if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted: print("Speech synthesized for text [{}]".format(text)) stream = speechsdk.AudioDataStream(result) stream.save_to_wav_file("out.mp3") elif result.reason == speechsdk.ResultReason.Canceled: cancellation_details = result.cancellation_details print("Speech synthesis canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) |
L3~L4: 輸入的你key和區域, 從 Azure 的範例裡會有幫你貼好,忘了可直接參考
L7: 指定要輸出的格式是 mp3, 若不指定的話,會直接念出來
L8: 要轉換的文字
L15~L16: 存檔成 mp3
結語
微軟的這個語音效果的確很不錯,連我都想考慮進軍youtube內容農場的隊伍了。原來我每天看的影片,都是這樣來得啊~~


){kind=link}