本文要介紹的是一個 GPT2 的聊天機器人實現,參考的專案是 GPT2-chiachat。由於該作者同時還開發了幾個專案,也會在本頁面上做更新,所以看起來會有點亂。讀者可以直接找「 UPDATE 2020.01.09」,來查看他的原文,找到聊天機器人的部份。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 |
conda create -n gpt2-chitchat python=3.9 |
下載專案
首下就用 git 將其下載下來
|
1 2 3 4 5 |
cd projects git clone https://github.com/yangjianxin1/GPT2-chitchat.git cd GPT2-chitchat echo "conda activate gpt2-chitchat" > env.sh source ./env.sh |
這邊我們下載專案的同時,也將其所需的額外目錄建立起來。另外也產生 env.sh 檔案,來切換 conda 環境。往後要使用本專案時,就先執行。
|
1 |
source ./env.sh |
安裝套件
接著安裝專案所指定的套件,需要對 requirements.txt 做一些修改
- pytorch 改成torch, 指定的版號拿掉。
- sklearn 改成 scikit-learn
- scipy 版號拿掉
|
1 |
pip install -r requirements.txt |
另外再安裝過程中也會缺的
|
1 2 3 4 |
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c nvidia -y pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113 pip install tensorflow chardet pip install transformers==4.26.1 pandas jieba scikit-learn |
專案目錄
其中幾個比較重要的目錄
- data: 放置要訓練的語料,預設是 train.txt。再經過 preprocess.py 處理後,會產生 train.pkl,這才是真正要使用的檔案,這與 GPT2-Chinese 中的 raw 參數意義差不多。
- model: 訓練後儲存 model 的位置。
- vocab: 放置字典檔的地方。若要新增自己的字典檔,可以先前一篇的 GPT2-Chinese 處理過後在放過來,原始專案的語料是簡體中文。
- sample: 放置聊天的Log
語料格式
此專案的語料格式,是以空白行來當做區分
|
1 2 3 4 5 6 7 8 9 |
早安啊 你也早 今天天氣好嗎 我沒出門不知道耶 . . . |
作者有提供幾個語料可以下載的
- 常見中文閒聊: 這也是一個專案,裡面有收集一些語料,而且還附有預處理的程式碼。我試過感覺雜訊較多,沒仔細測試
- 50萬中文閒聊語料: 已有預處理
- 100萬中文閒聊語料: 已有預處理
由於下面50萬和100萬的 Google Drive 連結已失效,這邊我提供自己下載的,供大家參考。
解開已下載好的語料,並將其轉換成繁體中文。
|
1 2 3 |
unzstd -c /cache/common/datasets/chat_100w.tar.zstd | tar xv mv chat_100w/train_100w.txt data/train.txt zhTW.sh data/train.txt |
由於語料轉成繁體了,字典也要轉成繁體
|
1 |
zhTW.sh vocab/vocab.txt |
程式修改
由於原程式train.py沒有產生最後一次訓練模型的功能,這邊我們自己把它功能補上去。先找到 “save model” 這個字,然後加上下面程式碼。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
-- GPT2-chitchat/train.py 2023-02-24 07:28:26.825460864 +0800 +++ projects/GPT2-chitchat/train.py 2023-02-23 21:32:32.148212174 +0800 @@ -217,6 +217,13 @@ os.mkdir(model_path) model_to_save = model.module if hasattr(model, 'module') else model model_to_save.save_pretrained(model_path) + + model_path = join(args.save_model_path, 'final') + if not os.path.exists(model_path): + os.mkdir(model_path) + model_to_save.save_pretrained(model_path) + print("save to final") + logger.info('epoch {} finished'.format(epoch + 1)) epoch_finish_time = datetime.now() logger.info('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time)) @@ -398,6 +405,8 @@ model = GPT2LMHeadModel(config=model_config) model = model.to(device) logger.info('model config:\n{}'.format(model.config.to_json_string())) + print(model.config.vocab_size) + print(tokenizer.vocab_size) assert model.config.vocab_size == tokenizer.vocab_size # 并行??模型 |
語料預處理
將語料檔案放在 data/train.txt 下面,然後以下面命令來做預處理,並把結果存到 data/train.pkl。
|
1 |
python preprocess.py --train_path data/train.txt --save_path data/train.pkl |
訓練模型
要訓練模型前,要先修改一下設定檔的字典個數。這問題目前還不大清楚,自行計算的字數和 tokenize 後的不一樣。先手動修改 config/config.json 裡的 vocab_size 成 11821 。本文的效果是用預設的字典產生的,所以應該還可以正常運行。
這個 vocab.txt 其實可以透過 AI 學習紀錄 – GPT2 Chinese 裡面提供的 make_vocab.sh 來產生,但資料還是要經過一點處理。我用金庸+WiKi產生出的字典檔,可以在這裡下載,再覆蓋掉 vocab/vocab.txt,然後把config的 vocat_size 改成 53664.
接著就下達以下命令來進行測試
|
1 |
python train.py --epochs 40 --batch_size 32 --device 0 --train_path data/train.pkl |
參數跟之前的 GPT2 Chinese 的用法差不多,就不在描述。
若已經有之前訓練過的結果,也是用 pretrain 的參數來指定
|
1 2 3 4 5 6 7 8 9 |
#!/bin/bash if [ -e model/final/pytorch_model.bin ];then PRETRAIN="--pretrained_model model/final/" echo "Use Pretrained Data" sleep 1 fi python train.py --epochs 40 --batch_size 32 --device 0 \ --train_path data/train.pkl $PRETRAIN |
以RTX4090來測試,一個epoch約要1小時。
開始聊天
下達以下參數,來開始進行聊天
|
1 |
python interact.py --no_cuda --model_path model/final --max_history_len 3 |
聊天由於比較不佔資源,可以 CPU 運算即可(no_cuda),這樣方便部署。若要使用 GPU,則改用device參數來指定。
執行效果
可以看到第10回訓練後,比第1回好了很多
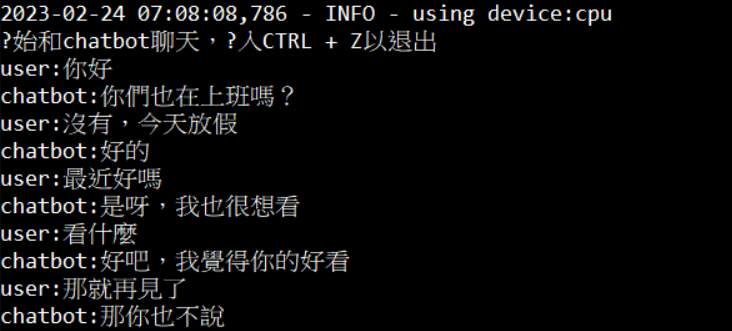
訓練第一輪的聊天
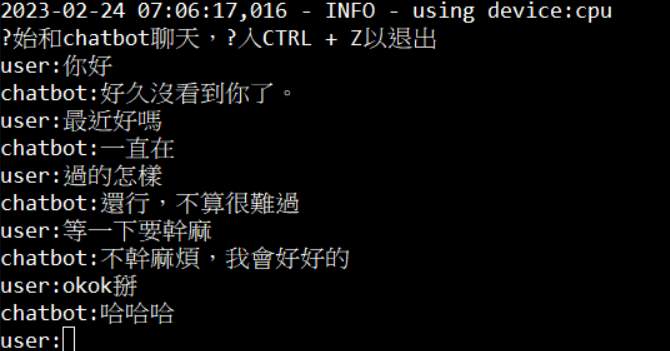
訓練第10輪的聊天



{kind=link}