接下來的幾篇文章,都是比較利用網上分享的算法所產生的模型。但話可以說在前頭,效果都不太好。但做為學習的目的,還是直得研究一翻。第一個就是 GPT2 Chinese 的這個專案。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 |
conda create -n gpt2-chinese python=3.9 |
GPT2 Chinese
GPT2 Chinese 是用 GPT2 進行中文語料的訓練,這邊的語料主要是金庸的小說,完整的中文教學可以參考這個 Youtube 影片。其使用的程式碼是來自這裡。下達以下命令,以進行下載。其使用的是比較舊的版本,而非最新版(master),所以下載位置要注意一下。
|
1 2 3 4 5 6 7 |
cd projects git clone https://github.com/Morizeyao/GPT2-Chinese.git cd GPT2-Chinese git checkout old_gpt_2_chinese_before_2021_4_22 mkdir data model echo "conda activate gpt2-chinese" > env.sh source ./env.sh |
這邊我們下載專案的同時,也將其所需的額外目錄建立起來。另外也產生 env.sh 檔案,來切換 conda 環境。往後要使用本專案時,就先執行。
|
1 |
source ./env.sh |
安裝套件
接著安裝專案所指定的套件
|
1 2 |
sed -i 's/sklearn/scikit-learn/g' requirements.txt pip install -r requirements.txt |
另外再安裝過程中也會缺的
|
1 2 3 |
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c nvidia -y pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113 pip install tensorflow gdown chardet |
小說語料
小說語料可以在這篇文章的最下方可以下載,但其僅做為研究使用,勿隨意散佈。下載後,是一個 json 格式的檔案,由於其是一行到底,在觀察上會很困難。可以透過 linux 指令「jq」將其較好的格式化成一行一篇。語料也可以使用WiKi的資料,但內容比較多,可能要裁掉一些內容,以減少VRAM需求或訓練時間。
|
1 2 |
cat /cache/common/datasets/jinyong.json.xz | xz -d > jinyong.json #本行請改成自己的位置 cat jinyong.json | jq > a.json |

接著將語料檔放在固定位置
|
1 |
mv a.json data/train.json |
產生 vocabulary 檔案
將剛剛產生的 a.json 檔案,覆蓋 data/train.json 檔案,然後進入 cache 目錄內,執行 ./make_vocab.sh,來針對剛的語料產生字典檔。
|
1 2 3 |
cd cache chmod a+x make_vocab.sh ./make_vocab.sh |
字典檔還有分好幾種,這邊是比較簡單的一行一個。其產生的檔名為 vocab_user.txt。
|
1 2 3 4 |
python make_vocab.py \ --raw_data_path ../data/train.json \ --vocab_file vocab_user.txt \ --vocab_size 50000 |
上面的內容,就是 make_vocab.sh。產生字典檔的命令裡,其中的 vocab_size 是最多允許的個數。最後在進行訓練時,越多的字數就會佔用較多的記憶體 (但也沒到1:1線性增加這多)。

產生完字典檔後,要將其行數給記下來,以取代設定檔內的設定。算行數的命令為
|
1 2 |
cat vocab_user.txt | wc -l cd .. |
修改設定檔
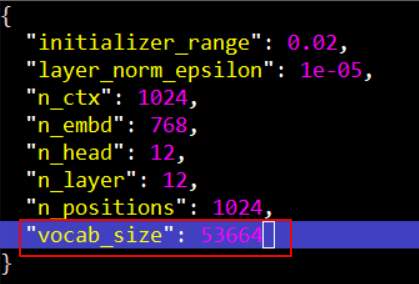
接著修改設定檔案 config/model_config.json,將其字典的大小改成剛剛算出來的數字。
開始進行訓練
我訓練的命令,是把它另外放在一個 shell script 裡面,這裡就對其進行解說。建立的指令,與內容如下
|
1 2 |
touch train.sh chmod a+x train.sh |
內容
|
1 2 3 4 5 6 7 8 9 |
#!/bin/bash if [ -e model/final_model/pytorch_model.bin ];then PRETRAIN="--pretrained_model model/final_model/" echo "Use Pretrained Data" sleep 1 fi python train.py --device=0 --epochs=3 --batch_size=1 --min_length=10 --raw_data_path=data/train.json --output_dir=model/ $PRETRAIN \ --model_config=config/model_config.json \ --tokenizer_path=cache/vocab_user.txt #--raw |
L2~6: 由於訓練是一個重複很多次,且漫長的流程,通常不會一次就做完。GPT2-Chinese 會將每一輪的訓練 (每個epoch)訓練出來的模型,放在 model/ 內。而最後一次的,則會放在 model/final_model內,所以若存在之前的結果。我們就會使用 –pretrained_model 參數,來繼續前次的訓練。
L7: 主要的訓練參數
- device: 要使用的 GPU 編號,只有一張 nvidia 卡就是 0
- epochs: 要訓練幾輪
- batch_size: 每次要訓練幾筆資料,可以想成越多就需要越多記憶體。
- min_length: 一句話至少要多長才行訓練。由於我們的語料一行都很長,這個可以不用更改
- raw_data_path: 指向我們要訓練的語料檔
- output_dir: 要儲存訓練出來的模型位置。每一個 epoch 的結果都會儲存
- $PRETRAIN: 這個就是前面提到會自行判斷是否有 pretrained 的資料,若不存在 model/final_model,那這邊就會是空的,而進行重新訓練。
- model_config: 設定檔的位置
- tokenizer_path: 字典檔的位置
- #raw: 進行第一個 epoch 訓練時,這個要打開。其會將 train.json 分成100分,並將每一個詞用字典檔的單字詞index取代。由於這個過程還蠻花時間的,在第一次新訓練時,要先手動打開,之後再關掉即可。若model_config, tokenizer_path 或 raw_data_path 指定的檔案內容有變更過,這步驟就要重做,不然訓練到一半可能會有錯誤
第一次運行
上面是 train.sh 裡的內容,原則上第一次要去把 #raw 這行做修改。如果不想手動改的話,就直接用下面命令來產生 token. 最後會報錯可以忽略,因為這把它的 epoch 設為0的關係。
|
1 2 3 |
python train.py --device=0 --epochs=0 --batch_size=0 --min_length=10 --raw_data_path=data/train.json --output_dir=model/ $PRETRAIN \ --model_config=config/model_config.json \ --tokenizer_path=cache/vocab_user.txt --raw |
產生文本
這邊產生的文本,會把小說拼來湊去,看起來像人工寫的,訓練多輪後的效果會比較好。這邊一樣是用一個我自己在用的 shell script 來說明。一樣先產生檔案,然後把內容貼進去
|
1 2 |
touch generate.sh chmod a+x generate.sh |
內容
|
1 2 3 4 5 6 7 8 9 |
#!/bin/bash term=$1 if [ "$term" = "" ];then term="張無忌見三名老僧在片刻間連斃崑崙派四位高手," fi python generate.py --length=150 --nsamples=3 --prefix="$term" --temperature=0.7 \ --model_path=model/final_model/ \ --model_config=config/model_config.json \ --tokenizer_path=cache/vocab_user.txt |
L2~5: 設定開頭的文字,模型會自動把話接下去。若第一個參數為空,就會用預設的句字。
L7: 主要的產生的參數
- length: 要產生的文章長度
- nsamples: 要產生幾篇文章
- prefix: 就是2~5行指定的文章開頭
- temperature: 變化度,越接進1就越隨機。
- model_path: 指向訓練的最後一次 epoch 結果,也可以使用中間過程的來試試看進步的程度。
- model_config: 模型的設定檔,與訓練時的相同
- tokenizer_path: 字典檔,與訓練時的相同
訓練結果
嘗試做了50個epoch, batch=4, 4090每一輪花費15分鐘。挑了幾個epcoh給大家看看結果
|
1 2 3 4 5 |
張無忌見三名老僧在片刻間連斃崑崙派四位高手,心想這小小僧的武功雖然不及, 但見他的 臉上卻已不禁的神色,不由得心中更是驚懼。這老僧又道:「不是。」 但聽他又道:「這位 姑娘說道士說得好,不是你們跟我們說過。」郭靖道: 「好,好罷啦!」郭靖道:「你說話 ,不是。」郭靖道:「不是。」 郭靖道:「我說得不得。」一燈哈哈哈大笑,道:「這位姑 娘是個女子,怎麼又不是? |
|
1 2 3 4 5 6 |
張無忌見三名老僧在片刻間連斃崑崙派四位高手,心下更是凜然,暗想: 「這三名老僧的武 功實在深不可測,他三人的招式之中,隱伏必有 極特極厲害的後著,我若是只守不攻,一敵 三人便抵擋不住。當世上 武功最厲害的,除了這四名高手之外,只怕其餘四人都要擋他三人 。 倘若他三人聯手,只怕三人自己非輸不可。」他心念微動,腳下卻 慢慢加重,絲毫不敢有 絲毫輕忽。又過一會,兩人 |
|
1 2 3 4 5 6 |
張無忌見三名老僧在片刻間連斃崑崙派四位高手,舉重若輕,游刃有餘, 自己這一出手,真 是不自禁的又驚又喜,何況他生具異相,乃是可怖 可畏。他想圓真能有多少時候,我當再來 看他。」說道:「少林派的 玄慈大師呢?」縱身而前,伸手往圓真的頸中抓去。這一抓也是 極快 ,只聽得嗤嗤聲響,圓真的笑聲已在數丈之外。 《靈蛇秘傳》金剛拳法中有柔,游坦之一抓不中,手臂不聽使 |
|
1 2 3 4 5 6 |
張無忌見三名老僧在片刻間連斃崑崙派四位高手,接拳給了那個老僧, 以「一字慧」字訣相 傳,心道:「原來這三位老僧便是崑崙派的、 崑崙派的何太沖。我倒是不可輕敵,四個老僧 更加不識。」那 老僧持刀而立,只聽得噹噹噹三聲響,高高矮矮,共有三十餘名僧人, 一色 的濕氣。衛四娘大聲叫道:「崑崙和尚,你怎知我們是誰?」 何太沖臉上變色,心想毀了這 一路武功,非圖禪杖可敵, |
|
1 2 3 4 5 6 |
張無忌見三名老僧在片刻間連斃崑崙派四位高手,舉重若輕,游刃有餘, 武功之高,實是生 平罕見,比之鹿杖客和鶴筆翁似乎猶有過之, 縱不如太師父張三丰之深不可測,卻也到了神 而明之的境地, 當下舉起屠龍寶刀,叫道:「俞二張,接刀!」將倚天劍擲了過去。 宋遠橋 正要伸手接住,突然間俞蓮舟的一聲慘呼,煙霧中一股白煙 被噴上了雙頰,急忙替他裹傷。 張松溪道:「無忌孩兒,你 |
結語
這個 GPT2-Chinese 目前感覺還是以玩玩居多,語句也接的有些奇怪,但是第一個epoch和後來的也是可以看到明顯的進步。



{kind=link}