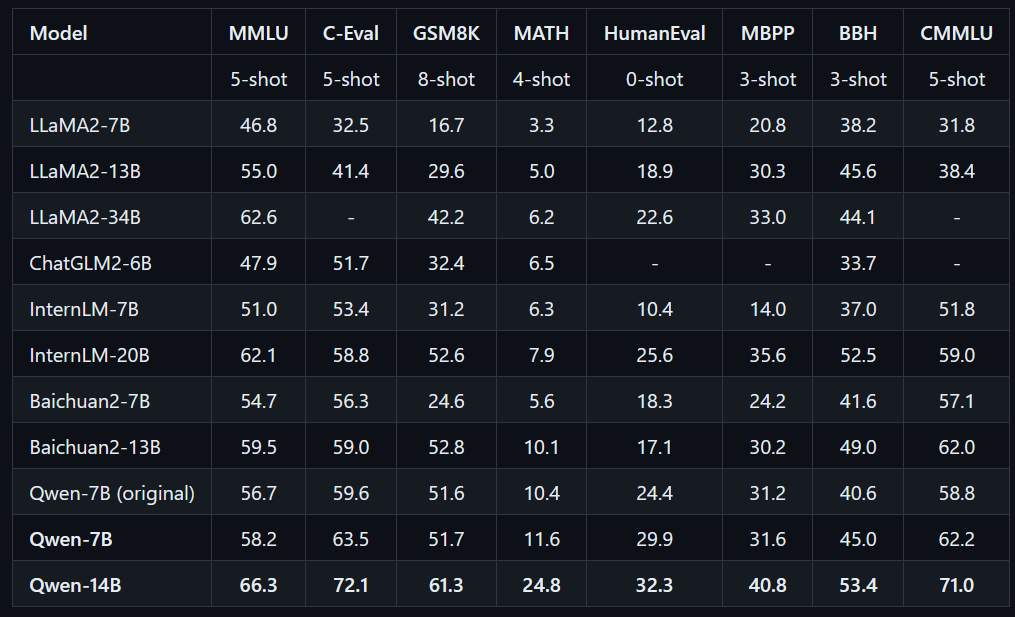
I have tried several large language models before, including chatGLM2, Baichuan2, and Llama. Recently, I also saw a powerful Alibaba model called QianWen (Qwen). The experimental data on the QianWen website shows that its performance is generally better than other open-source models.
The translation comparison using chatGLM2 feels like the level of a junior high school student, while Qwen’s translation is closer to general writing standards. Of course, there is a difference in model size, so this comparison may not be fair. But it can still serve as a reference for everyone. The results can be viewed at: “chatGLM2 translation article” and “Qwen translation article“.
But just playing around with a large language model seems a bit cliche. In this article, we will use Qwen to automatically translate and publish WordPress articles, truly turning AI into productivity.
Basic environment installation
Some basic environmental settings, such as Anaconda and shared scripts, have already been written in the article “Common Operations” at this link. Please take a look first to ensure that all commands can be executed correctly.
Create a Conda environment
Due to the different dependencies of each project, an environment will be set up for each case here.
|
1 2 |
conda create -n qwen python=3.8 conda activate qwen |
Download project and model
|
1 2 3 4 5 6 7 8 |
git clone https://github.com/QwenLM/Qwen cd Qwen echo "conda activate qwen" > env pip install -r requirements.txt pip install -r requirements_web_demo.txt pip install optimum auto-gptq OpenCC==1.1.0 BeautifulSoup4 sudo apt-get install tidy git clone https://huggingface.co/Qwen/Qwen-14B-Chat-Int4 |
Download the quantized version model of Qwen-14B-Chat-Int4 directly here, with a file size of about 9GB and taking up around 13GB VRAM in actual operation.
Execute WEB Demo
Edit the file named “web_demo.py” and find the following line. Replace the original model path with “Qwen-14B-Chat-Int4”.
|
1 |
DEFAULT_CKPT_PATH = 'Qwen/Qwen-7B-Chat' |
Then, run the following command.
|
1 |
web_demo.py --server-name 0.0.0.0 -c Qwen-14B-Chat-Int4 |
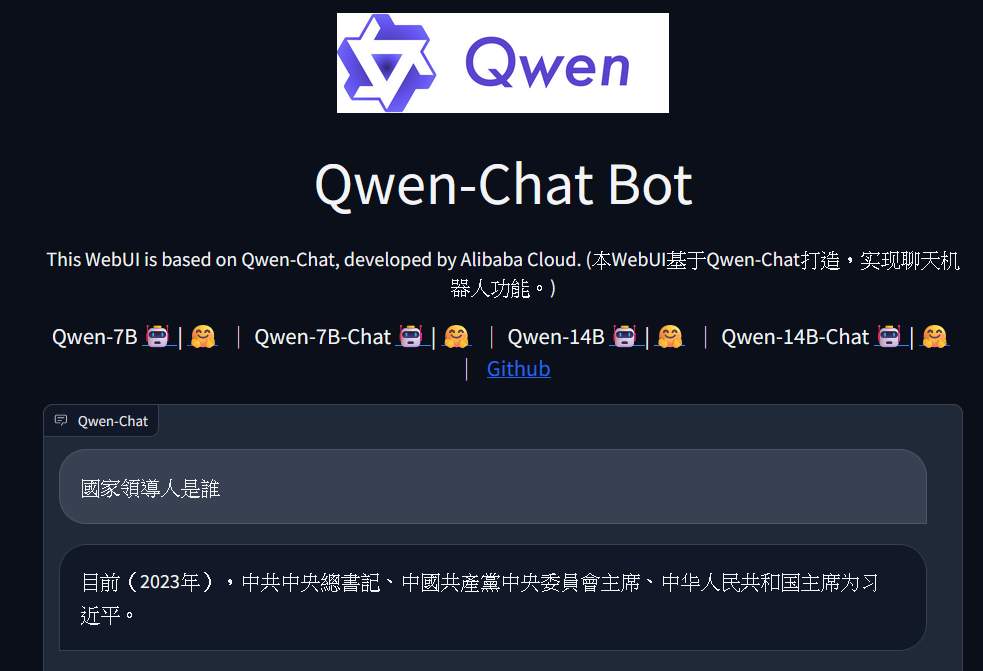
After that, you can open http://IP:8000 in your browser to try out the web chat interface. By the way, I asked a question that has been quite popular recently… People are different, and one grain of rice can raise hundreds of people. With the same data, similar models will be generated.
WordPress article translation script
To call Qwen’s dialogue function, I modified the example script cli_demo.py. In fact, most key functions of large language models are quite simple, and many programs are focused on optimizing user interfaces. Here is my translation program.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 |
# -*- coding: utf-8 -*- import os import platform import shutil from copy import deepcopy import sys import re import time import torch from transformers import AutoModelForCausalLM, AutoTokenizer from transformers.generation import GenerationConfig from transformers.trainer_utils import set_seed import codecs from bs4 import BeautifulSoup DEFAULT_CKPT_PATH = 'Qwen-14B-Chat-Int4' from opencc import OpenCC s2t = OpenCC('s2t') t2s = OpenCC('t2s') seed=0 def has_chinese(msg): chset=re.compile('[\u4e00-\u9fff]+').findall(msg) if len(chset) == 0: return False return True def is_failed(src, rsp): invalid_keywords = [ "sorry", "Sorry", "抱歉", "請提供"] invalid_keywords = invalid_keywords +[ "translation incomplete", "<http", "Please provide"] for i in invalid_keywords: if rsp.find(i) != -1: set_seed(round(time.time())) return 1 if src.find("<a href=") != -1 and rsp.find("<a href=") == -1: set_seed(round(time.time())) return 1 return 0 def translate_retry(content): if has_chinese(content) == False: #print(f"tag {content} 沒有中文", file=sys.stderr) return content i=0 for i in range(20): rsp = translate(content, 0, config) #.replace("\n", "") if is_failed(content, rsp) == 1: continue break if i >= 19: print(f"翻譯失敗: {content} --> {rsp}", file=sys.stderr) rsp = content #sys.exit(1) #print(f"translate_tag {tag}: {match} --> \n{rsp}\n ", file=sys.stderr) content = content.replace(content, rsp) set_seed(seed) return content def translate_tag(content, tag): tag_name=tag pattern = rf'<{tag_name}>(.*?)</{tag_name}>' matches = re.findall(pattern, content, re.DOTALL) for match in matches: set_seed(seed) #match = match.replace("\n", "") if has_chinese(match) == False: continue i=0 for i in range(20): rsp = translate(match, 0, config) #.replace("\n", "") if is_failed(match, rsp) == 1: continue break if i >= 19: print(f"翻譯失敗: {match} --> {rsp}", file=sys.stderr) rsp = match #sys.exit(1) #print(f"translate_tag {tag}: {match} --> \n{rsp}\n ", file=sys.stderr) content = content.replace(match, rsp) set_seed(seed) return content def load_model_tokenizer(): tokenizer = AutoTokenizer.from_pretrained( DEFAULT_CKPT_PATH, trust_remote_code=True, resume_download=True, ) device_map = "auto" model = AutoModelForCausalLM.from_pretrained( DEFAULT_CKPT_PATH, device_map=device_map, trust_remote_code=True, resume_download=True, ).eval() config = GenerationConfig.from_pretrained( DEFAULT_CKPT_PATH, trust_remote_code=True, resume_download=True, ) return model, tokenizer, config def translate(query, i, config): history = [] if i == 199: query = f"這句話「{query}」的英文翻譯是什麼.\n\n" prepend="" else: prepend = '把下面的中文內容翻譯成英文, 不要有額外的說明.\n\n' response, history = model.chat(tokenizer, prepend+query, history=history, generation_config=config, past_key_values=None) all = " " + response+ " " return all model, tokenizer, config = load_model_tokenizer() f = codecs.open(sys.argv[1], "r", "UTF-8") in_pre = False while True: line = f.readline() if len(line) == 0: break line = line.replace("\n", "") if line.find("<pre") != -1: in_pre = True print(line) if line.find("</pre") != -1: in_pre = False continue if line.find("</pre") != -1: print(line) in_pre = False continue if in_pre == True: print(line) continue if line.find("ul>") != -1: print(line) continue if line.find("<li>") != -1: line = translate_tag(line, "li") print(line) continue if line.find("<h3>") != -1: line = translate_tag(line, "h3").replace(".", "") print(line) continue if line.find("<h4>") != -1: line = translate_tag(line, "h4").replace(".", "") print(line) continue if line.find("<h5>") != -1: line = translate_tag(line, "h5").replace(".", "") print(line) continue rsp = translate_retry(line) if is_failed(line, rsp) == 1: print("失敗: " + line + "--->" + rsp, file=sys.stderr) print(rsp) f.close() sys.exit(0) |
The descriptions of functions:
- has_chinese(): This method checks whether there is Chinese or not. If there is no Chinese, it means that there is nothing to do.
- is_failed(): The function is used to determine whether the translation has failed. Due to the randomness of AI translation, such as answering irrelevant questions or deleting important parts, it is necessary to first judge and decide whether to adopt its output result. This function is closely related to the model you use. If different LLM models are adopted, the error type may be different.
- The
translate_retry()function processes the translation line by line and calls this function if it does not find some specified HTML tags. The “retry” means that after each translation, it uses theis_failed()function to check, if the failure occurs more than 20 times, it will output the original text. - translate_tag(): Translate the content of the specified tag for translation. Currently used for headings (h) and lists (ui).
- “load_model_tokenizer()” is a function that loads a model tokenizer obtained from a CLI example.
- translate(): Calls the model to perform translation.
The operation process can be briefly described as follows:
- First load the model and then read in the file to be translated line by line.
- If there is a “pre” tag found, output it directly because WordPress uses it to output the original format of the mark. To avoid translating the content in between, all the content in between should be outputted as is.
- If there is a discovery of ul tag, output directly.
- “If encountering a
litag, the content in the middle will be translated.” - for h3~h5,they are processed like li
- for others, just translate.
Translation
A typical execution instruction is as follows:
|
1 |
python ai_translate_new.py article.txt > all.html |
Here, ai_translate_new.py refers to the above program, and article.txt represents the original content of the WordPress article. This content can be seen in the WordPress compiler and saved as article.txt.
Due to the fact that my WordPress is an older version and I have no intention of upgrading to a newer one, the tags that appear frequently in my articles are very simple. The newer versions of WordPress seem to have more user-friendly live editing tools, but these tools often add many tags, which can cause AI translation to be prone to errors. If you do not need to translate into English, using the new tool is fine, or you will need to handle exceptions for your translation program more.
If there is a failure during the translation process, the failed sentence will also be displayed.
The final content will be redirected to an “all.html” file for inspection.

The translation cannot be completed because the message contains HTML tags that cannot be translated. The original message and the translated message will be displayed. Since I set a rule in is_failed() that does not allow links to disappear, it was judged as a failure. After translation, you can check for any HTML abnormalities using a tool called tidy.
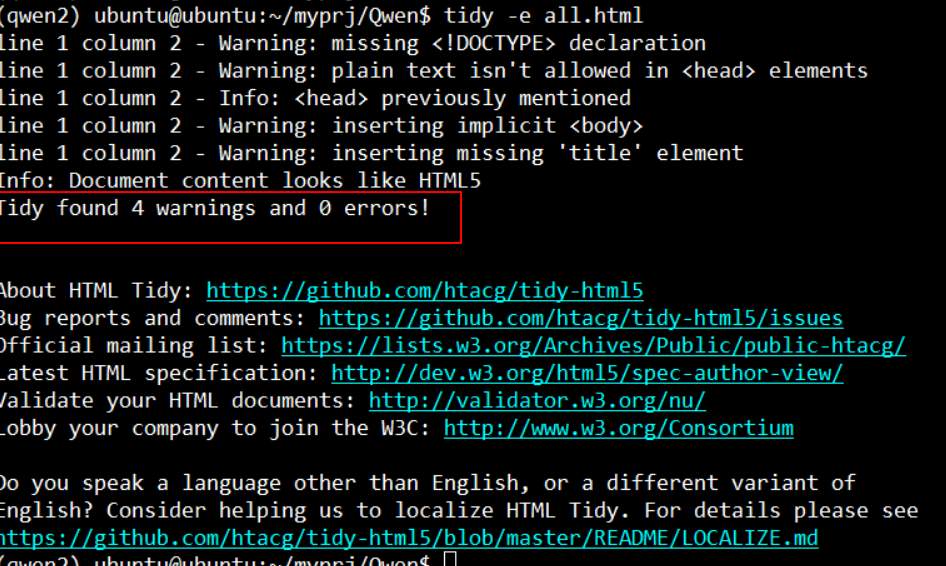
Through the number of errors in this tool, we can roughly understand whether there are major errors. If so, it will list the line numbers of the errors. At this time, we can optimize the automation program by modifying the rules of is_failed() in ai_translate_new.py, or we can simply manually correct them.
After the basic check with tidy, you can directly open this all.html file to see its content and whether there are any obvious errors.

If everything seems to be okay, you can manually paste this content into WordPress to create a new article.
WordPress automatically posts
Once we master how to automatically translate, we can then let WordPress automatically post articles. WordPress has a set of CLI tools that can be used to read article lists and content, but this is only applicable for self-hosted WordPress with a server. If you use some WordPress without CLI, it may not apply, but you can still do so by translating and then posting on the web.
WP CLI
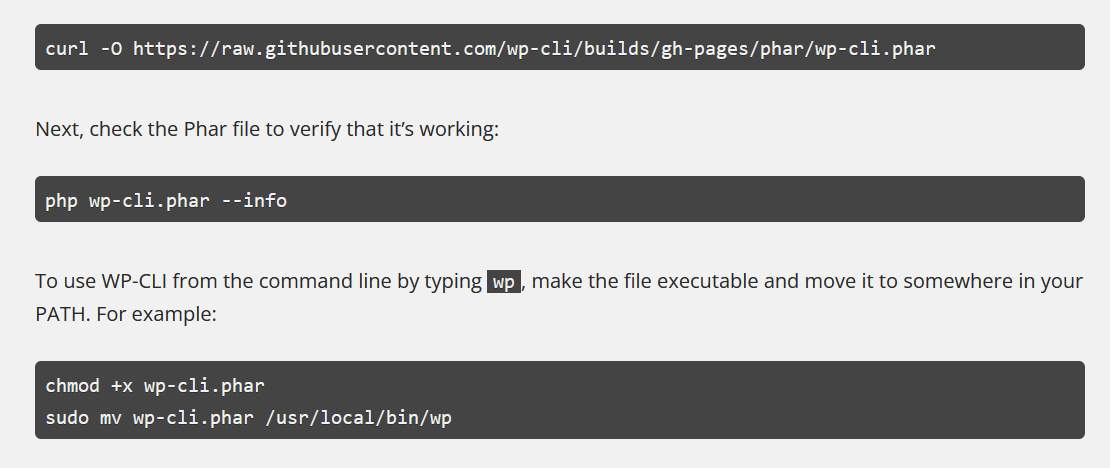
The command-line installation method for WordPress is as follows, which is actually just downloading the file and placing it in the /bin directory.
WP CLI Remote
It is clear that the hosting of WordPress and the AI host must be on different machines, so we need to obtain data from WordPress remotely for translation. This aspect is also explained on the official WordPress website here, simply put, you need to create a ~/.wp-cli/config.yml file and fill in the name and account information of the host.

The @prod in front is the name, host, and location represented by this group of accounts. When issuing WP Cli commands, you can use @prod to represent it, and its connection method to the host uses SSH. Those who use GCP to deploy WordPress can refer to this article for information on how to achieve passwordless remote login.
Auto-generated post
Finally, the automatic translation post I implemented was achieved through a script that specifies the ID to be translated and completes the task. The script first retrieves the article content, then translates it, and posts it if there is no error. The script for translating is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
!/bin/bash python ai_translate_new.py article.txt > all if [ $? -ne 0 ];then echo "#########################" echo "# AI Translate Error #" echo "#########################" exit 1 fi tidy -e all &> log cat log | grep "0 errors" &> /dev/null if [ $? -eq 0 ];then echo "#########################" echo "# Done #" echo "#########################" else echo "#########################" echo "# HTML Error #" echo "#########################" cat log | grep Error fi |
This is actually calling ai_translate_new.py to do the translation and then calling tidy to do a check.
The script for creating the post is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
#!/bin/bash POST_ID=$1 if [ "$POST_ID" = "" ];then echo "請提供要翻譯的文章 ID" exit 1 fi #wp @prod post list --fields=ID,post_title > all TITLE=`wp @prod post get $POST_ID --field=post_title` if [ $? -ne 0 ];then echo "讀取 $POST_ID 標題失敗" exit 1 fi wp @prod post get $POST_ID --field=post_content > article.txt dos2unix article.txt if [ $? -ne 0 ];then echo "讀取 $POST_ID 內容失敗" exit 1 fi echo "#### 翻譯標題 ####" sleep 1 ENG_TITLE=`python small_translate.py "$TITLE"` if [ $? -ne 0 ];then echo "翻譯成英文標題失敗" exit 1 fi echo "#### 開始翻譯內容 ####" sleep 1 ./translate.sh if [ $? -ne 0 ];then echo "翻譯內容失敗" exit 1 fi scp -i ~/.ssh/id_rsa all XXXXX@moon-half.info:/home/XXXXX/public_html/remote_post if [ $? -ne 0 ];then echo "複制檔案到遠端失敗" exit 1 fi NEW_ID=`wp @prod post create ./remote_post/all --post_title="$ENG_TITLE"` if [ $? -eq 0 ];then echo "發文成功. 文章 ID $NEW_ID" exit 0 else echo "發文失敗" exit 1 fi |
This part mainly uses the post title, content, and publishing features of WP CLI to automate tasks. In each step, failure scenarios are considered to provide feedback to users.
Translation tips for automatic translation:
In order to make AI translation more prepared, I found that it is best to simplify the formatting used. For example, in WordPress, only a few tags such as pre, h3-h5, ui, and ol are used. Perhaps the current AI translation is not very perfect, but through some small tricks, it can still work for you.
Conclusion
Using open-source AI large language models can indeed save a lot of time and not rely on paid services, but the knowledge required is indeed considerable. I have always felt that users need to master certain CLI technology skills so that they can turn technology into their hands. If only through others’ APIs or GUIs, your balls are actually held in others’ hands. APIs can change at any time, and GUIs do not have automation capabilities, which means these abilities cannot be mastered by you.
Someone said “AI will not replace you, but people who know how to use AI will.” I hope everyone can master the skills of using these large models more flexibly.

{kind=link}