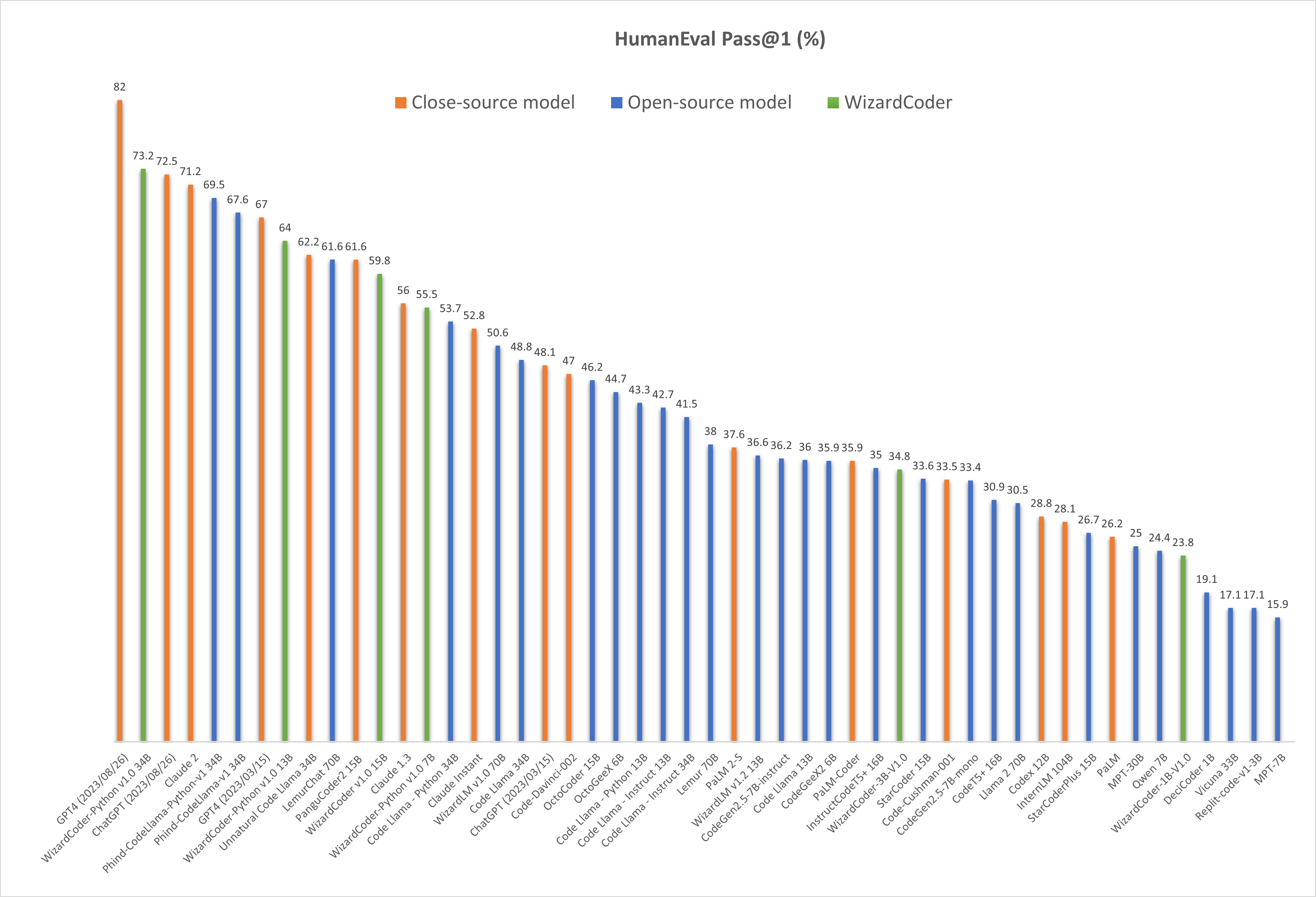
Lllama 是 Meta 推出的語言大模型,其第2代 Lllama2 也有 7B, 13B, 與 70B的大尺寸。其自身也有產生程式的 codellama2 與 衍生的 wizardCode 模型,在 python 方面有著70%以上的正確率,在其它語語也有50%以上的正確率,本文就紀錄怎麼使用這些模型。模型和 UI是分屬不同專案。
- UI 是名為 text-generation-webui 看來是想要打造一套統一大語言模型的文字產生器。
- Codellama: 這專案其實我沒怎麼看,因為好像沒介紹 UI
- Wizardcoder: WizardLM 裡面的 WizardCoder 子專案
為什麼 wizardCoder 比較好,還要介紹 CodeLlama 呢? 因為是在研究 CodeLlama 時發現的,而且還講的這麼神,就一起紀錄起來了。wizardCoder 的 github 滿篇都在教人家怎麼複現他的成果,使用方面反而少。看來是覺得自己東西很棒,怕又被當成騙人的,所以才重點放在複現上。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 2 |
conda create -n codegen python=3.10.9 conda activate codegen |
源碼下載與安裝環境
安裝下面套件。
|
1 2 3 4 5 6 |
git clone https://github.com/oobabooga/text-generation-webui cd text-generation-webui cd text-generation-webui pip3 install torch torchvision torchaudio pip install -r requirements.txt echo "conda activate codegen" > env.sh |
下載模型
這邊會下載2個Huggingface上的模型,一個是 Codellama2 (13B)的,一個是 WizardCoder (15B)的。他們都分都提供了不同的量化版本,差別就在大小、所需記憶體與精確度,這邊我都下載 8bit 的。
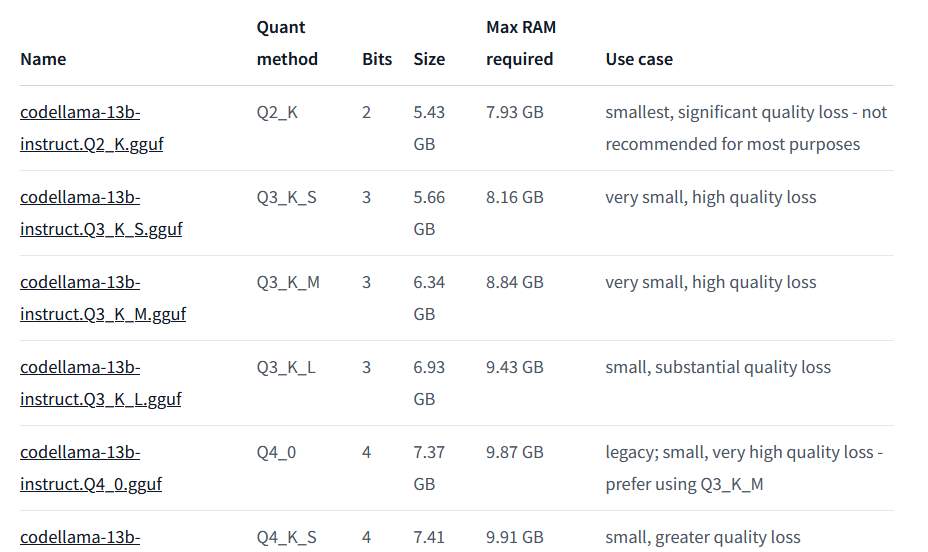
CodeLlama 模型表(部份截圖, 還有更多)
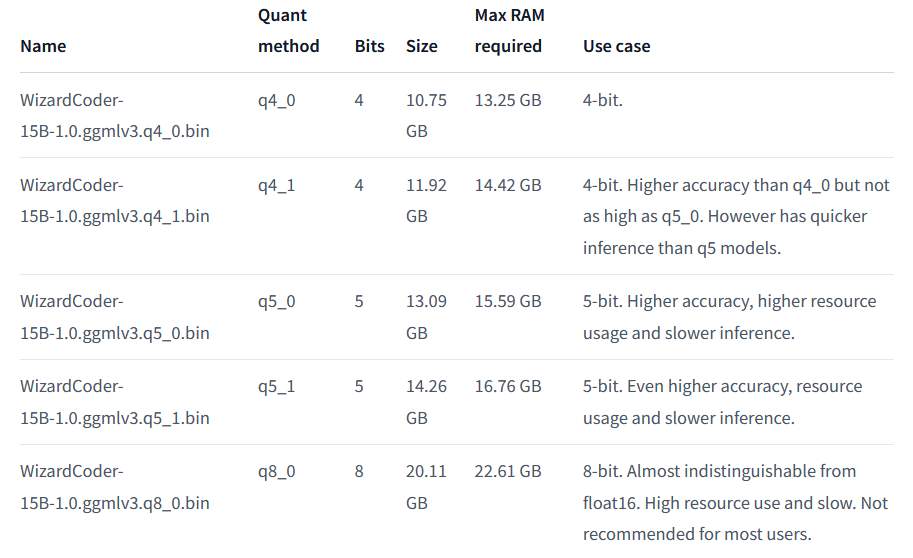
WizardCoder 模型
將下載的模型放到 models
|
1 2 3 4 5 |
cd models/ #下載 Codellama wget https://huggingface.co/TheBloke/CodeLlama-13B-Instruct-GGUF/resolve/main/codellama-13b-instruct.Q8_0.gguf #下載 WizardCoder https://huggingface.co/TheBloke/WizardCoder-15B-1.0-GGML/resolve/main/WizardCoder-15B-1.0.ggmlv3.q8_0.bin |
啟動模型
我們以 codellama 為預設啟動模型來解釋,進去後可以再切換。
|
1 |
python server.py --listen --model models/codellama-13b-instruct.Q8_0.gguf --n-gpu-layers 42 |
- –listen: 任何IP都可以連線,不然只能從本地
- –model: 要預先載入的模型
- –n-gpu-layers: 要預先載入的 GPU 的層數。預設是不載入,所以一開始使用的時候發現GPU都沒動,完全用CPU。這個數值要自己試一下,看看到哪個程度不會爆 VRAM。
這2個參數都是可以進去後再調,但是現在還沒這麼懂他的UI,先記下來。
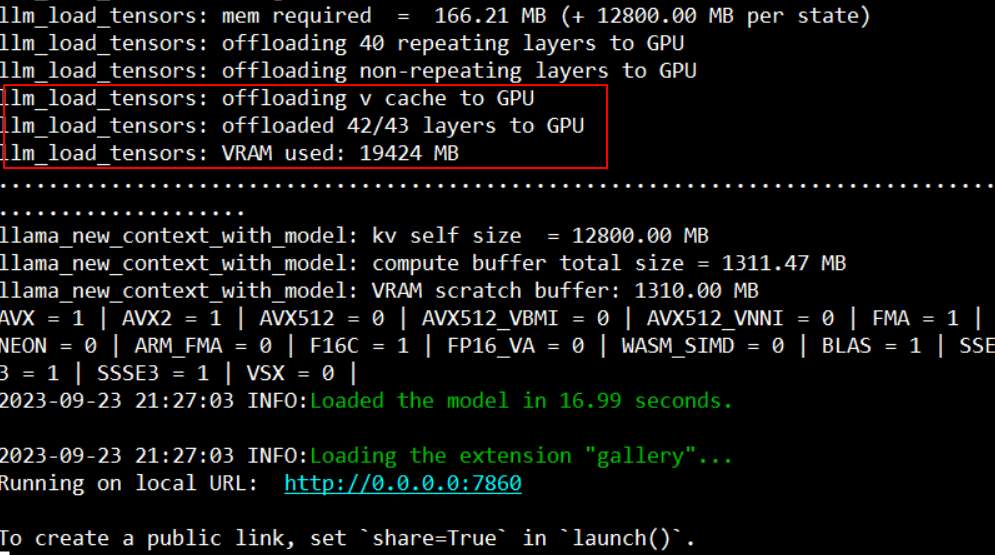
載入GPU的大小
WEB UI 使用
text-generation-webui 為相容多個模型,畫面頗為複雜. 一開始連進去後直接就是聊天畫面。
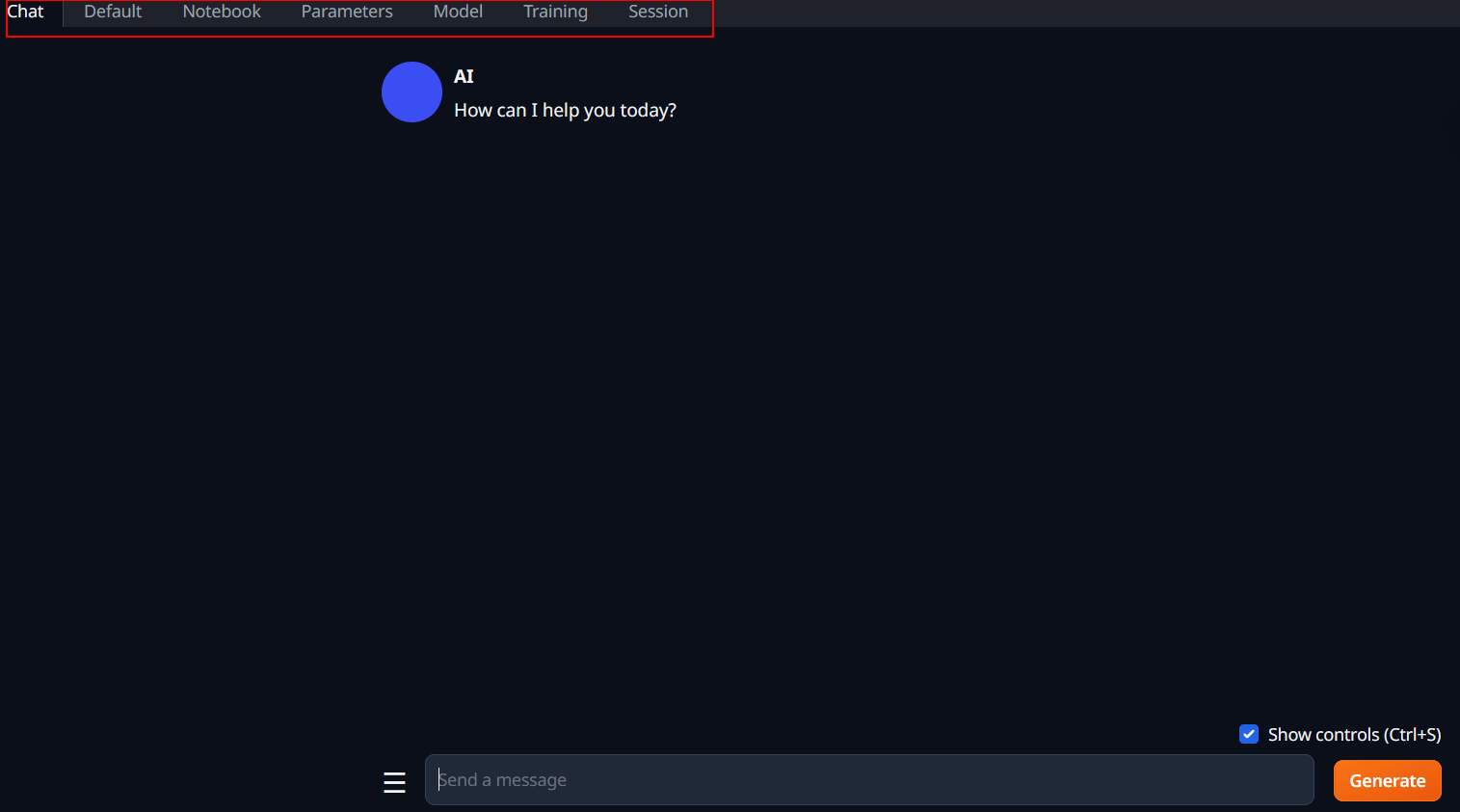
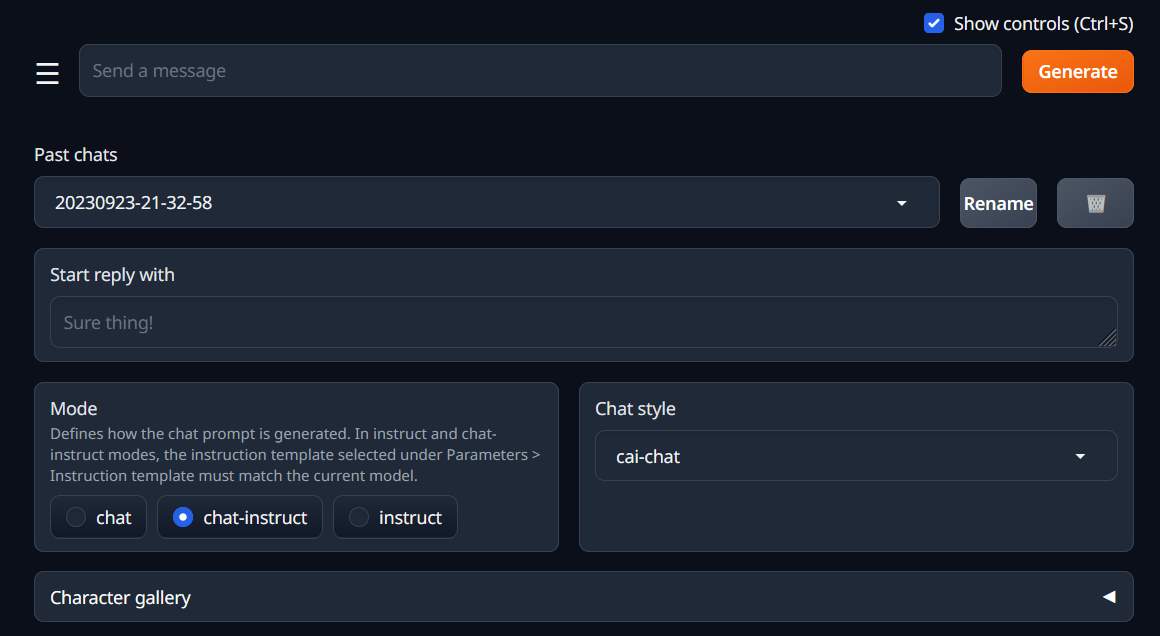
這邊就直接講要改的部份。
- 將 chat 分頁,最下面的 mode ,改成 chat-instruct或instruct。感覺 instruct 比較不會廢話,直接給程式。chat-instruct 有時會講一堆原理
- Parameters 分頁,將 max_new_token 設成最大 (4096),然後按下磁碟片圖示存檔。這個設置可能會增加記憶體使用,所以若有問題可以調整看看。設長一點,才能讓他回答的內容變長,不然常常講到一半就停了。
接著就可以回到 chat 頁面要程式碼了。我要了一個 「please write a quick sort algorithm in C language」,前面回答的還不錯,但後來就卡了,動不了,不知道是不是設置有問題。 Console 也沒看到什麼錯誤訊息。
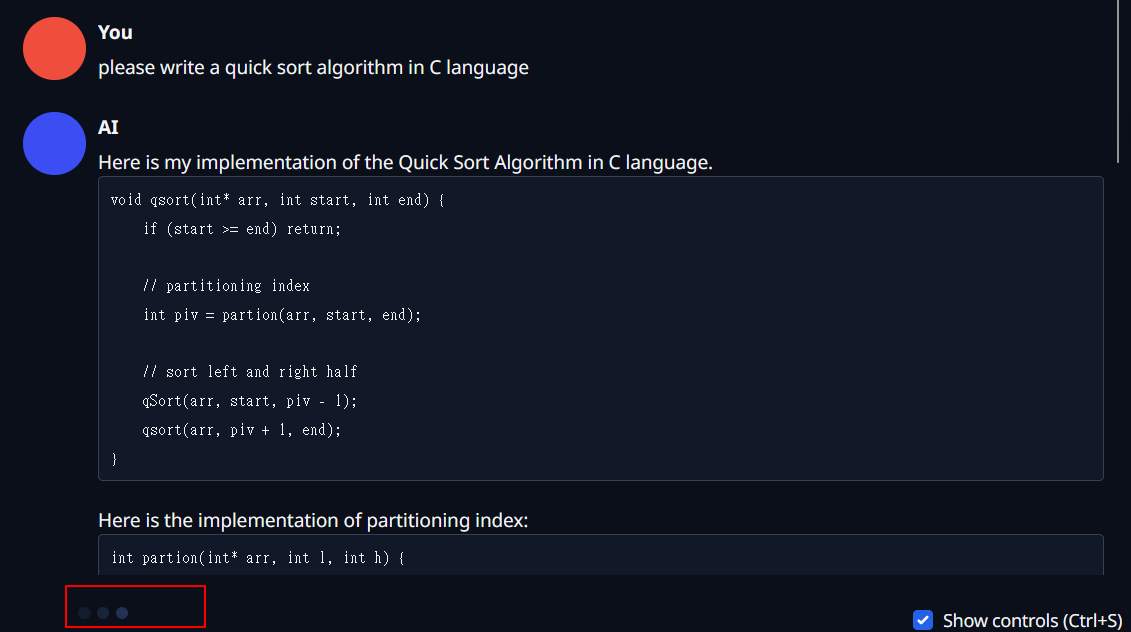
產生到一半卡住
使用 WizardCoder
接著到 Model 頁面
- Model 選擇 WizardCoder
- Model Loader 選擇 ctransformers, 先錯就載不進來
- 按下 reload
成功後,就會顯示載入成功(右下角部份)
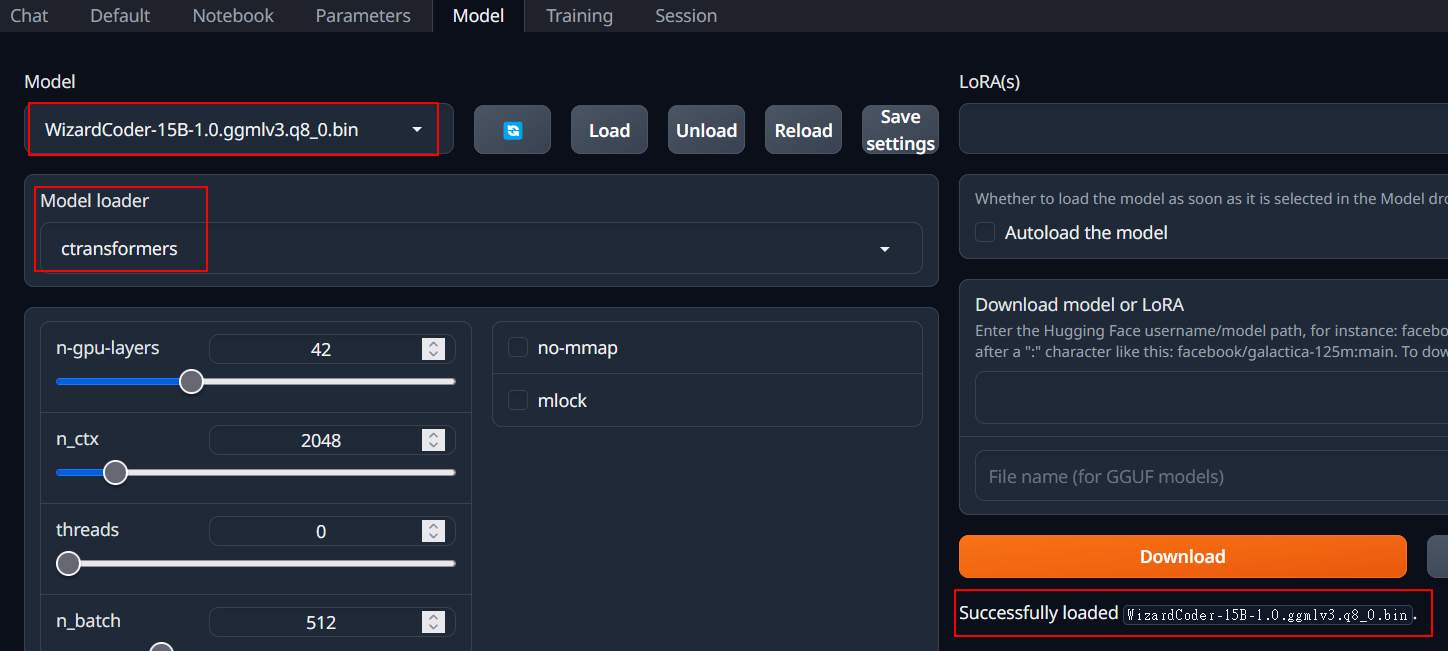
這樣就可以回到 chat 頁面要程式了。
其它
感覺這個程式組合目前還不太成熟,但成功的時候可以看出程式寫的還行。但有時會出現類似下面這種道德違規的說法,但下幾次後又可以了,可能程式的設置也需要再研究一下。

這個 text-generation-webui 感覺還可以載入其它的聊天模型,像我之前研究的 GLM 或 Baichuan,值得再研究看看。這樣切換就很方便了,也比 langchain 可設定的參數多很多。


{kind=link}