這是由前篇文章「chitchat 聊天機器人」的同作者的另一個專案,其所利用的 CPM (Chinese Pretrained Model) 是基於 GPT2 的中文版本,原本是 TsinhuaAI 所發佈的。作者利用該模型,訓練語料來產生作文、小說、新聞等等。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 |
conda create -n cpm python=3.9 |
專案下載
下達以下命令來進行 clone
|
1 2 3 4 5 |
cd projects git clone https://github.com/yangjianxin1/CPM.git cd CPM echo "conda activate cpm" > env.sh source ./env.sh |
目錄說明
- config: 存放模型的設定文件
- data: 存放訓練的語料,本案的訓練樣本是文章,所以會在子目錄以一個檔案一篇文章的方式來存放。
- model: 訓練後模型放置的地方
- vocab: 放置字典的位置。本案的字典是以 sentencepiece 所產生,所以還要預先做處理。
這邊我們下載專案的同時,另外也產生 env.sh 檔案,來切換 conda 環境。往後要使用本專案時,就先執行。
|
1 |
source ./env.sh |
安裝套件
|
1 2 3 4 5 |
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c nvidia -y pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113 pip install tensorflow chardet pip install transformers==4.26.1 pandas jieba scikit-learn pip install sentencepiece |
語料下載
要訓練的語料,是以個別的 .txt 檔案存在,內容格式如下
|
1 2 3 4 5 6 7 8 |
-- 標題:大家好 日期:xxxx-xx-xx xx:xx:xx 作者:沒有人 -- 大家好,我是一篇文章。 |
若讀者要使用自己的語料,請案照上面格式存檔。原作者有提供26萬篇的作文語料,放在百度空間上,但由於檔案壓縮後超過 200MB,無法在這提供各位下載,請見諒。有百度、微信的朋友,可以在作者的文章上 回覆公眾號以獲取 link 。
|
1 |
项目代码以及使用方法,可以访问项目Github地址。在公众号后台回复【003】获取笔者训练好的模型权重与26w篇中文作文数据集。数据集仅供学术交流,请勿用于商业用途。 |
語料處理
個人的語料處理方式,是將其在 data/ 解壓後,改名成 zuowen,裡面就是27萬個檔案了。
|
1 2 3 4 5 6 |
cd data zstd -d -c /cache/common/datasets/articles_27w.tar.zstd | tar x mv articles_27w/ zuowen rm -f all.txt find zuowen/ -exec cat {} >> all.txt \; cd .. |
另外,由於在產生字典檔時需要把所有文章合成一個檔案,上面的指令也將其合併成 all.txt (27萬篇文章會有點久)
以 sentencepiece 產生字典檔
這案的字典檔是以 sentencepiece 產生,所以需要另外下載該專案來處理。
以下列命令下載 與編譯(原專案為 https://github.com/google/sentencepiece)
|
1 2 3 4 5 6 |
git clone https://github.com/google/sentencepiece.git cd sentencepiece mkdir build cd build cmake .. make -j $(nproc) |
編譯完後,執行下列命令,來進行字典檔的產生。
|
1 2 3 |
./src/spm_train --input=../../data/all.txt --model_prefix=my \ --vocab_size=50000 --character_coverage=1 --model_type='unigram' \ --num_threads=16 --user_defined_symbols="__,<sep>,<pad>,<mask>,<eod>" |
其中
- input: 要產生字典檔的原始文件
- model_prefix: 產生字典檔的檔案前綴字
- vocab_size: 最多幾個字
- character_coverage: 不太瞭解,網上是說中文用1
- user_defined_symbols: 不太瞭解,參考原案的字典檔,將這些元補齊
- model_type: 可以設成 bpe 或 unigram,大概就是字和詞的區別,具體我不太懂,可以參考這裡。因為 unigram 才能多執行序運行,所以這邊就選 unigram。選 bpe 只能用單執行序,要執行很久。
完成後就會產生 my.json 與 my.vocab 檔。將其覆蓋預設的檔案.
|
1 2 3 |
cp my.model ../../vocab/chinese_vocab.model cp my.vocab ../../vocab/chinese_vocab.vocab cd ../.. |
然後修改設定檔 config/cpm-small.json,將其 vocab_size 改成 50000。若語料比較少,可能會少於5萬,實際個數可看 vocab/chinese_vocab.vocab 一共有幾行。
語料預處理
接著要將語料做預處理
|
1 2 |
python preprocess.py --data_path data/zuowen --save_path data/train.pkl --win_size 200 --step 200 |
- data_path: 存放語料的目錄
- save_path: 預處理後要存成的檔案
- win_size, step: 可參考原始碼或原作者的專案頁面,這邊不做更動
進行訓練
在進行訓練前,要修改一下train.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
--- CPM/train.py 2023-02-24 13:55:25.009822670 +0800 +++ train.py 2023-02-24 13:53:30.312779909 +0800 @@ -48,7 +48,7 @@ parser.add_argument('--max_grad_norm', default=1.0, type=float, required=False) parser.add_argument('--save_model_path', default='model', type=str, required=False, help='模型?出路?') - parser.add_argument('--pretrained_model', default='model/zuowen_epoch40', type=str, required=False, + parser.add_argument('--pretrained_model', default='', type=str, required=False, help='???的模型的路?') parser.add_argument('--seed', type=int, default=1234, help='?置?机种子') parser.add_argument('--num_workers', type=int, default=0, help="dataloader加??据?使用的?程?量") @@ -158,6 +158,10 @@ os.mkdir(model_path) model_to_save = model.module if hasattr(model, 'module') else model model_to_save.save_pretrained(model_path) + + model_path = join(args.save_model_path, 'final') + model_to_save.save_pretrained(model_path) + logger.info('epoch {} finished'.format(epoch + 1)) epoch_finish_time = datetime.now() logger.info('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time)) @@ -269,6 +273,9 @@ model = GPT2LMHeadModel(config=model_config) model = model.to(device) logger.info('model config:\n{}'.format(model.config.to_json_string())) + + print(model.config.vocab_size) + print(tokenizer.vocab_size) assert model.config.vocab_size == tokenizer.vocab_size # 多卡并行??模型 |
再建立以下的 script 來進行訓練。
|
1 2 3 4 5 6 |
#!/bin/bash if [ -e model/final/pytorch_model.bin ];then PRETRAIN="--pretrained_model model/final" fi python train.py --epochs 8 --batch_size 16 --device 0 --gpu0_bsz 16 \ --train_path data/train.pkl $PRETRAIN |
一個epoch花時約30分鐘。
產生文章
|
1 2 |
python generate.py --title "家鄉" --context "家鄉的四季,最美不過了" \ --max_len 200 --model_path model/final |
- title: 文章的標題
- context: 文章的開頭
- max_len: 產生的文章長度

Epoch 1
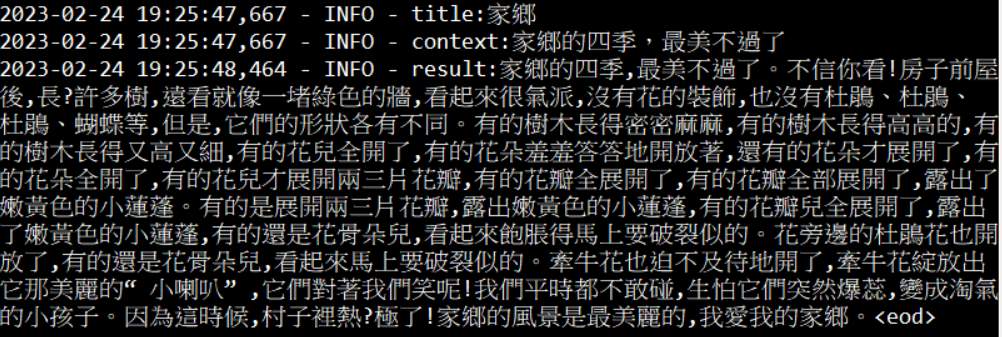
Epoch 5
結語
不知道是訓練不夠多次,還是AI就是沒這麼聰明。對於預設的標題內容,寫的還蠻好的。但是如果自創一個 “清晨”, “清晨是一天的開始,是人人該把握的時間”,寫出來的就不佳。應該是原本的語料裡就沒這個類似的文章。


{kind=link}