本文要介紹的也是 github 上的一個專案「ASRT_SpeechRecognition」,可以識別中文語音轉成文字。我猜想應該也是可以識別英文語音轉文字,就看你給他訓練的檔案是哪種。
這應該是算比較傳統的方法,先用對答案的方式訓練,也就是需要標記的。不過語音辨識的標記比較好取得,電影、youtube 字幕都有很多材料。
目前已有較準確的辨認專案,請參考 AI 學習紀錄 – PPASR 語音識別
專案下載
|
1 2 3 |
git clone https://github.com/nl8590687/ASRT_SpeechRecognition.git cd ASRT_SpeechRecognition mkdir -p data/speech_data |
下載訓練語音檔的標記文件
|
1 |
python download_default_datalist.py |
本文是要使用”AIShell-1″數據集來做訓練,所以只要下載其標記即可。若要全部下載也無妨,這方面的數具不大。
下載語音數據集
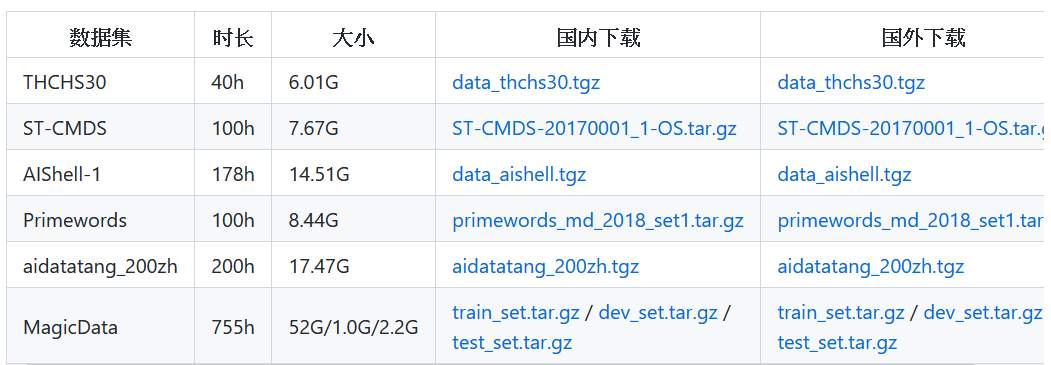
在原作者是專案頁下,有提供幾個數據集可供下載,我看大部份是 host 在 openlsr 的網站,也有更多的數據集可以參考。這邊下載 「AIShell-1, 178hr, 14.5G」的這個數據集,下載位置在這。
下載後,以下列命令解壓縮。原文沒有寫到對wav下的每個壓縮檔做解壓,這邊做了一點點的修改。
|
1 2 3 |
tar zxf data_aishell.tgz -C data/speech_data/ cd data/speech_data/data_aishell/wav find . -name "*gz" -exec tar zxf {} \; |
修改設定檔
由於預設的設定檔 (asrt_config.json),是針對所有的數據集做訓練,所以這裡要做一下修改,把沒用到的數據集設定拿掉,只留下 aishell。修改後的內容如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
{ "dict_filename": "dict.txt", "dataset":{ "train":[ { "name": "aishell_train", "data_list": "datalist/aishell/train.wav.lst", "data_path": "data/speech_data", "label_list": "datalist/aishell/train.syllable.txt" } ], "dev":[ { "name": "aishell_dev", "data_list": "datalist/aishell/dev.wav.lst", "data_path": "data/speech_data", "label_list": "datalist/aishell/dev.syllable.txt" } ], "test":[ { "name": "aishell_test", "data_list": "datalist/aishell/test.wav.lst", "data_path": "data/speech_data", "label_list": "datalist/aishell/test.syllable.txt" } ] } } |
開始訓練
接著就可以執行下列命令來進行訓練,預設是做 50 個 epoch,RTX4090 做一個 epoch 大概是15分鐘,辨識效果還算滿意。
|
1 |
python train_speech_model.py |
準確率測試
這邊可以用測試命令來測試其準確率,大概是65% 左右,我不確定他怎麼測的。以我的標準是音有接近,前後的字至少要有一二個是對的就好。
|
1 |
python3 evaluate_speech_model.py |
單詞測試
用下面指令,隨意複制一個 wav 成 filename.wav,再執行辨識程式,就可以得到結果
|
1 2 3 |
cp data/speech_data/data_aishell/wav/train/S0002/BAC009S0002W0147.wav filename.wav python3 predict_speech_file.py |
服務器模式
要使用 http server / client 來做辨識的話可以先執行 server
|
1 |
python3 asrserver_http.py & |
再透過 client 程式辨識, 裡面的wav檔名要依自己需求修改 (read_wav_bytes)。 `
python3 client_http.py



{kind=link}