本篇要介紹的是另一個語音識別專案 PPASR,一個基於飛槳的專案。由於之前試用的 ASRT 中文語音識別 效果不太好,用 sample 檔辨識不錯,但由我自己錄的聲音卻是一團糟。
今天介紹的這個 PPASR,直接提供了線上即時辨識的Demo,試用後覺得不錯,就clone下來研究了。目前只是直接使用其 model 而已,尚未做自己的訓練。以語音辨識而言,如果辨識率不錯,其實也未必要自己訓練。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 |
conda create -n paddle python=3.9 |
專案下載
使用下面的命令,將專案下載下來,並建立環境切換檔。
|
1 2 3 4 5 6 |
cd projects git clone https://github.com/yeyupiaoling/PPASR cd PPASR echo "conda activate paddle" > env.sh echo 'export LD_LIBRARY_PATH=$HOME/anaconda3/envs/paddle/lib/:$LD_LIBRARY_PATH' >> env.sh source ./env.sh |
安裝環境
接著安裝專案所指定的套件, 該專案後面有一篇是「快速安裝」,下面的說明內容參考自該頁面。這個專案做的蠻不錯的,說明很齊,真的要給星。

詳細的教學文件
依面下命令,逐個安裝套件
|
1 2 3 4 |
conda install paddlepaddle-gpu==2.4.1 cudatoolkit=11.7 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge python -m pip install ppasr -U -i https://pypi.tuna.tsinghua.edu.cn/simple python -m pip install paddlespeech_ctcdecoders -i https://ppasr.yeyupiaoling.cn/pypi/simple/ conda install -c "nvidia/label/cuda-11.8.0" cuda-toolkit #依自己cuda版本更新 |
最後一行又裝了 cuda-11.8.0 的 toolkit,是因為我的 cuda 版本就是 11.8 ,讀者也可以依自己所使用的版本安裝。Anaconda 的官方支援 cuda-toolkit 在這裡。
下載數據集
專案裡的「快速使用」有說明如何下載數據集與預處理,這邊我們就下載 thchs_30 這個數據集,可用下面的命令來進行下載。不過由於裡面的網址是連到大陸去的,所以下載會慢到動不了。
|
1 2 |
cd download_data/ python thchs_30.py |
要替換下載網址,就編輯 thchs_30.py 這個檔案,修改 DATA_URL 到其它網站,若本地端已下載過,也可以用 file:// 的方式來指向本地檔案。
|
1 2 3 4 5 6 7 8 |
from utility import add_arguments, print_arguments #原本大陸站 #DATA_URL = 'https://openslr.magicdatatech.com/resources/18/data_thchs30.tgz' DATA_URL = 'https://www.openslr.org/resources/18/data_thchs30.tgz' #本地檔案 #DATA_URL = 'file:///cache/common/datasets/data_thchs30.tgz' MD5_DATA = '2d2252bde5c8429929e1841d4cb95e90' |
下載完成後,以下列命令來預處理資料
|
1 2 |
cd .. python create_data.py |
其中第一行,也請加到 ~/.bashrc 內,裡面的 ‘paddle’ 要改成自己取的虛擬環境的名稱。
測試語音辨識
依專案的範例,建立一個 a.py
|
1 2 3 4 5 6 7 8 |
from ppasr.predict import PPASRPredictor predictor = PPASRPredictor(model_tag='conformer_streaming_fbank_wenetspeech') wav_path = 'dataset/test.wav' result = predictor.predict(audio_data=wav_path, use_pun=False) score, text = result['score'], result['text'] print(f"识别结果: {text}, 得分: {int(score)}") |
執行 python a.py 後,會開始下載另一個model。若之前有下載過,且也有存檔的話,可以將其複製到 lm/ 目錄下,就不用再下載。
|
1 2 |
mkdir lm cp /cache/common/models/paddle/zh_giga.no_cna_cmn.prune01244.klm lm/ |
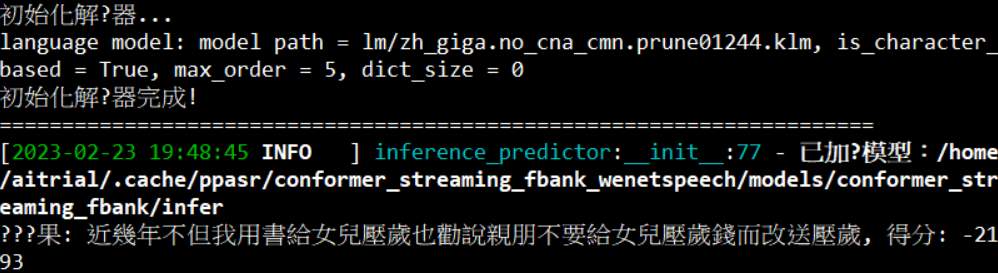
辨識結果
使用 web 做串流式辨識
本來想下載專案的AISHELL預訓練模型,但需要csdn的帳號與付費,這邊先暫時略過。直接用前面單句預測的, 將之前單詞預測的模型下載下來的模型,複製到本地端來。
|
1 2 |
cp -a /cache/.cache/ppasr/conformer_streaming_fbank_wenetspeech/* . #cp -a /cache/common/models/paddle/conformer_streaming_fbank_wenetspeech/* . |
其中的 /cache 目錄,是我自己的 softlink。一般應該會在 $HOME/.cache/ppasr 下面。
接著執行下列命令, server 就會啟動。
|
1 |
python infer_server.py |
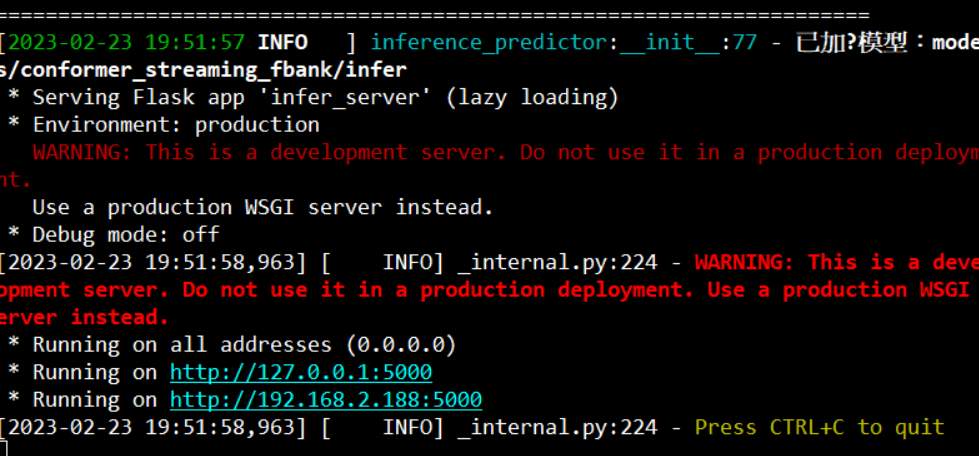
然後可依提示連接到 127.xxx 或 192.xxx 的網頁去。如果你是在本機實驗,就連到 127.x 的就好,不用做任何設定。若是連到 192.x 的,就要開啟瀏覽器另外的設定,因為現在瀏覽器預設不允許透過 http 來錄音。

辨識結果
local 的辨識結果沒有線上來的好,可能是模型還是不同的吧。就如同之前所說的, CSDN 上面可以下載的可能比較好,也會收10人民幣左右。花了這麼多電訓練模型,其實也是蠻合理的。
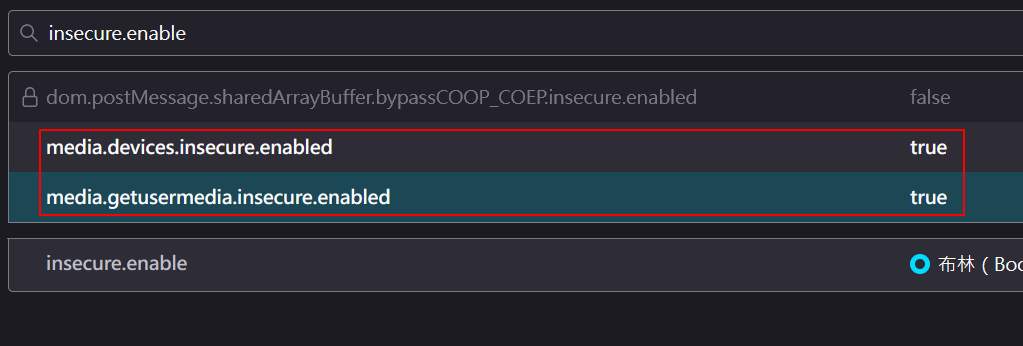
設定Firefox允許http錄音
要使用 firefox 進行 http 錄音,可以在網址列打 「about:config」。進到進階設定後,搜尋 insecure.enabled,然後把下面2項都打開。但這方法也只是每次錄音都要選擇「允許」,並無法一直記注選擇。若要一勞永逸,還是要再另外架設一個 https 的 server 來服務這固需求,快速的方法是利用 stunnel 來轉址,可以參考我寫的這篇文章。


{kind=link}