用了 CHAT GPT 後,就斷斷續續看了一些基本的 AI 基本 library 的用途介紹,包含
- pandas: 一維/二維陣列處理
- numpy: 多維陣列處理、矩陣乘法
- pillow: 圖型處理
雖然只看不用收獲不大,但對在看程式時還是有些幫助,接著就直接上了 GPT-J 的使用於調校。我在 Google Cloud 上試了各種機器組合,可以成功運行 (提問),也有可以調校的,但所需資源很大。以下是使用半精度 (FP16)的測試,
- 運行: 大概 CPU 64G RAM 配 T4 GPU(16G VRAM),可以運行。CPU RAM 如果不夠,可能是在一點 SWAP 就可以。
- 調校 (Finetune): 要 CPU 200G RAM 再開 64GB SWAP 才可以進行調校,GPU 我還是用 T4。因為 GCE 上只有T4可以單顆GPU配到208G的 CPU RAM。CPU 108G + 64G SWAP,還是會發生記憶體不足的問題。由於這種規格很燒錢,並沒有去確認調校有沒有用,其實我連調校都沒跑完。
由於 CPU RAM 108G 仍然不夠,所以可以推測在一般的主機板(最大128G),調校也是跑不起來。如果要用到 SWAP,那效率應該是極差,所以也就沒有再試下去了。狠心砸錢買 Server 的 8 DIMM 主機板好像也沒必要,一但三分鐘熱度過了就虧很大。
結論是:試用可以,調校不行。
會有下一篇是說明如何使用另一個修改版,只用 8bit 做處理,可以成功運行與調校。雖然是個失敗紀錄,但因為很多設定是重複的,就記下來了。後續也會用的到,或哪一天發財了,硬體升級時也跑的動。
硬體使用
上面是我在Google Colud 的 GCE 服務使用的效能分享,伺服器區域與配置如下
- 位置: asai-east1-a 台灣
- GPU: T4 16G VRAM
- Ubuntu 20.04, 200GHD
CPU 的話,N1 highmem 108G 或 200G的。
由於後來我自己架了機器 AI 學習紀錄 – 購入RTX4090主機,所以後面的文章,就以自己的機器設定方法為主。
環境安裝
以下就不廢話,直接給命令,包含初始化與套件安裝
基本套件
|
1 2 |
sudo apt-get update sudo apt-get install build-essential libaio-dev |
VIM 設定檔
編輯 ~/.vimrc
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
if has("autocmd") au BufReadPost * if line("'\"") > 1 && line("'\"") <= line("$") | exe "normal! g'\"" | endif endif :set shiftwidth=4 :set hls :set ts=4 :set viminfo='20,\"1000" :set ul=1000 :set bg=dark set guifont=courier_new:h12 :syntax on :set cursorline hi CursorLine term=bold cterm=bold guibg=Grey40 hi cursorLine term=none cterm=none ctermbg=4 set cscopetag :set fileencodings=utf-8,big5 if has('win32') colorscheme evening "noremap 在新版會顯示 warning, 似忽不需要了, set iminsert=0 endif |
SWAP Space
由於操作中容易記憶體不足,所以這邊也提供製做虛擬記憶體的指令,請自行調整需要大小,這邊是16G的指令。
|
1 2 3 |
sudo dd if=/dev/zero of=/swap.img bs=1G count=16 sudo mkswap /swap.img sudo swapon /swap.img |
安裝 Nvidia CUDA 11.3 與 Driver
|
1 2 3 4 5 6 7 |
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600 wget https://developer.download.nvidia.com/compute/cuda/11.3.1/local_installers/cuda-repo-ubuntu2004-11-3-local_11.3.1-465.19.01-1_amd64.deb sudo dpkg -i cuda-repo-ubuntu2004-11-3-local_11.3.1-465.19.01-1_amd64.deb sudo apt-key add /var/cuda-repo-ubuntu2004-11-3-local/7fa2af80.pub sudo apt-get update sudo apt-get -y install cuda |
最後編譯可能會錯誤,請套用下面修改(參考這裡)
- /usr/src/nvidia-465.19.01/common/inc/nv-time.h: 找到有 INTERRUPTIBLE 的這行,把整行換成 WRITE_ONCE(current->__state, TASK_INTERRUPTIBLE)
- /usr/src/nvidia-465.19.01/nvidia-drm/nvidia-drm-drv.c: 找到 to_pci,把整行移除
修改 /usr/src/linux-headers-5.15.0-1027-gcp/Makefile,把有 Werror 的部份都拿掉,這部份主要是不要讓 warning 變 error。kernel 的版本,請依據自己的機器修改一下,可以看 uname -r 。
完成後再重新執行一次 “sudo apt-get -y install cuda”
最後重新開機,讓 driver 載入。然後執行 nvidia-smi ,看是否有看到自己的顯卡。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 |
conda create -n gptj python=3.9 |
建立專案目錄
建立一個專案目錄
|
1 2 3 4 5 |
mkdir -p ~/projects/gptj cd projects/gptj echo "conda activate gptj" > env.sh echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HOME/anaconda3/envs/gptj/lib/' >> env.sh source ./env.sh |
安裝 Python 會用到的套件
|
1 2 |
pip install deepspeed accelerate tensorboard transformers chardet #pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113 |
|
1 2 |
conda install -c "nvidia/label/cuda-11.8.0" cuda-toolkit #依自己cuda版本更新 pip install torch tqdm opencv-python matplotlib datasets |
下載模型
雖然可以透過程式直接自動下載,不過這樣下次要再用的時候,又要重下載。因為檔案很大 (24GB),不太建議這樣做。這邊提供手動下載的方法。
|
1 2 3 4 5 6 7 8 9 |
mkdir model/ cd model/ wget -c https://huggingface.co/EleutherAI/gpt-j-6B/resolve/main/pytorch_model.bin wget https://huggingface.co/EleutherAI/gpt-j-6B/raw/main/config.json wget https://huggingface.co/EleutherAI/gpt-j-6B/raw/main/vocab.json wget https://huggingface.co/EleutherAI/gpt-j-6B/raw/main/added_tokens.json wget https://huggingface.co/EleutherAI/gpt-j-6B/raw/main/special_tokens_map.json wget https://huggingface.co/EleutherAI/gpt-j-6B/raw/main/merges.txt cd .. |
若已經下載好,並放在一起,就直接link過來即可。以下是我的筆記
|
1 |
ln -s /cache/common/models/gptj/model/ |
GPT-J 資料下載與測試
接著將下面的內容存成 test.py, 執行後就可以開始提問, 載入後約需要 13GB 的 VRAM
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import time import torch from transformers import GPTJForCausalLM, GPT2Tokenizer import torch import transformers from transformers import AutoTokenizer MODEL="model/" #MODEL="EleutherAI/gpt-j-6B" #Will need at least 13-14GB of Vram for CUDA if torch.cuda.is_available(): print("Cuda") model = GPTJForCausalLM.from_pretrained(MODEL, torch_dtype=torch.float16).cuda() else: print("Cpu") model = GPTJForCausalLM.from_pretrained(MODEL, torch_dtype=torch.float16) tokenizer = AutoTokenizer.from_pretrained(MODEL) model.eval() input_text = "Hello my name is Blake and" while True: input_ids = tokenizer.encode(str(input_text), return_tensors='pt').cuda() output = model.generate( input_ids, do_sample=True, max_length=200, top_p=0.7, top_k=0, temperature=1.0, ) print("電腦: " + tokenizer.decode(output[0], skip_special_tokens=True)) input_text = input("你:") |
GPT-J 調校 (Finetune)
這個步驟我沒完整跑完過,但確定可以運行,給讀者參考。
|
1 2 3 4 5 6 7 8 9 10 |
cd .. ln -s /usr/local/cuda-11.8/targets/x86_64-linux/lib/libcurand.so /usr/lib #請依自己 cuda 版本調整路徑 ln -s /usr/local/cuda-11.8/targets/x86_64-linux/lib/libcudart.so /usr/lib #請依自己 cuda 版本調整路徑 git clone https://github.com/mallorbc/Finetune_GPTNEO_GPTJ6B.git cd Finetune_GPTNEO_GPTJ6B git checkout a0641461077927c8b8ae73ae7fffa98d4f3899d3 cp quotes_dataset/*csv finetuning_repo/ #./install_requirements.sh # 前面已安裝過適當版本 cd finetuning_repo/ # source ./example_run.txt 不執行,使用我們自己的 |
由於 example_run.txt 太長,且有些參數要調,我建立自己的指令如下。
|
1 2 3 4 5 6 7 8 9 |
deepspeed --num_gpus=1 run_clm.py --deepspeed ds_config_gptj6b.json \ --model_name_or_path model/ \ --train_file train.csv \ --validation_file validation.csv --do_train --do_eval --fp16 --overwrite_cache \ --evaluation_strategy=steps --output_dir finetuned --num_train_epochs 1 \ --eval_steps 1000 --gradient_accumulation_steps 32 --per_device_train_batch_size 1 \ --use_fast_tokenizer False --learning_rate 5e-06 \ --warmup_steps 10 --save_total_limit 20 \ --save_steps 1000 --save_strategy steps --tokenizer_name gpt2 |
主要調整了
- model_name_or_path: 本來是指向 “EleutherAI/gpt-j-6B”, 這樣又會從網上download 25G, 所以這邊指向我們自己已 download 好的 model
- num_train_epochs: 本來是 12, 我改成1
- save_steps: 原本是1,我改成1000。存一次 checkpoint 要 25G ,吃不消,改成1000次,就是不要存.
- eval_steps: 從1改成1000,由於一次要40秒,有點浪費時間就把它關了。
由於速度過於緩慢,我只跑了一個epoch。實體的記憶體吃到了124G,虛擬記憶體大概吃了20G, VRAM至少要吃17G, 一次 evaluation 要花40秒。跑一個 epoch 下來,SSD 寫入了 2.4TB,記憶體不夠的還是玩不起。不過 pchome 上有在賣一條 128G的,就看有沒人口袋夠深了。
256G 記憶體
一個 epoch 一共跑了 1.5 小時,還算可以。但因為只訓練了一個 epoch,看起來怪怪的,太花時間就不研究了。結果如下, 紅色框代表一次對話。Finetune 的 log 在這邊,方便需要的人比對。
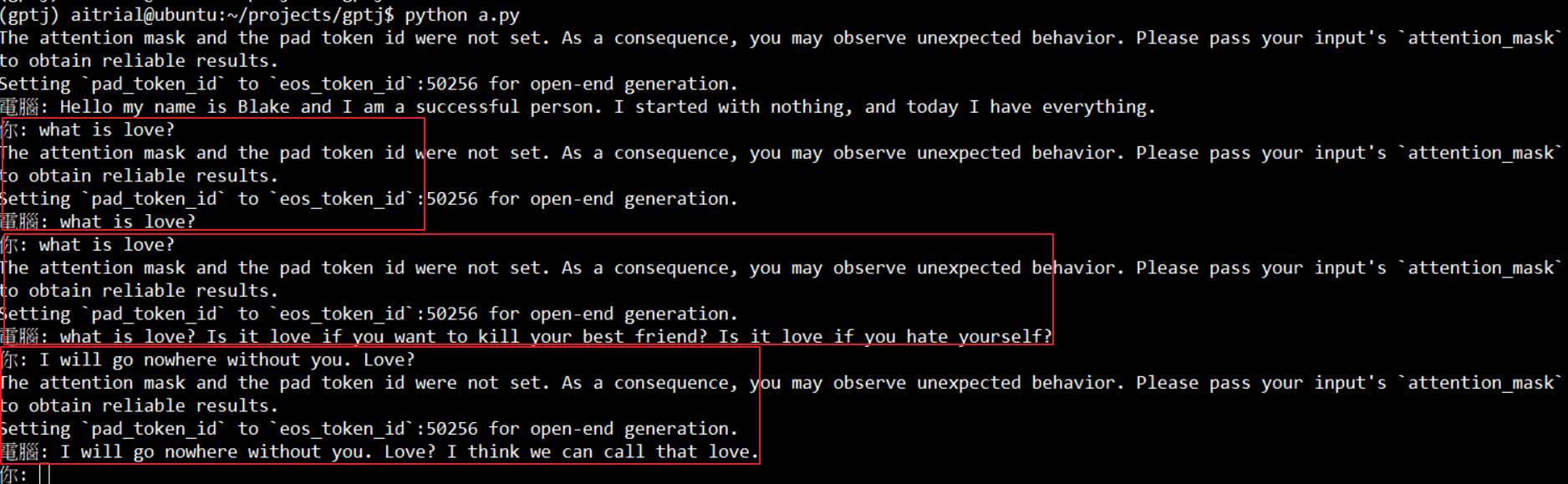
finetune 後對話
要使用 finetune 後的結果,將 Finetune_GPTNEO_GPTJ6B/finetuning_repo/finetuned/ 建立 link 到跟測試 script 同一目錄下即可。




){kind=link}