經過上一篇的學習紀錄,瞭解到了要利用一般平台進行 GPT 訓練,似乎是一項非常昂貴的任務,所以尋找了降級的辦法。所謂的降級辦法,就是把 fp16 改用成 int8 的方式,進一步降低 CPU RAM 的需求,而且據說對結果的影響不算大,所以我也試了一下。但還是沒有適當的硬體來評估是否真的可以,用 Google 的 GCE 壓力山大,所以只能匆匆的試了一下,可以運行,可以 finetune,但效果還不得而知。
同樣的,就先把步驟記下來,目前已經在考慮入手 NVIDIA RTX 4090 的,若有機會還是可以試一試。
系統安裝與設定
請先將前一篇的內容完成 Nvidia driver 的安裝「安裝 Nvidia CUDA 11.3 與 Driver」。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 |
conda create -n gpt8j python=3.9 |
下載 8bit gpt-j
接著,下載這個 8bit 的 project,以進行訓練,並安裝所需的檔案。如該專案所述,安裝所需 library
|
1 2 3 4 5 6 |
cd ~/projects git clone https://github.com/sleekmike/Finetune_GPT-J_6B_8-bit.git cd Finetune_GPT-J_6B_8-bit echo "conda activate gpt8j" > env.sh echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HOME/anaconda3/envs/gptj/lib/' >> env.sh source ./env.sh |
安裝套件
|
1 2 3 |
conda install -c "nvidia/label/cuda-11.8.0" cuda-toolkit #依自己cuda版本更新 pip install torch tqdm matplotlib datasets pip install -r requirements.txt |
其中 requirements.txt 的 bitsandbytes-cuda111 請改安裝 0.26.0.post2才行,請自行修改。
GPT-J 8bit 初始化
這個 gpt-j 要先下載 8bit 的 model 檔案,再進行訓練,所以需要自行修改不少東西,此處請參考下面內容,進行修改,所需的目錄,請先進行創建。
|
1 2 |
mkdir -p saved_models_gpt-j-6B-8bit/gpt-j-6B mkdir -p finetuned_gpt-j-8_bit |
下載預先訓練的 Model
跟之前的 AI 學習紀錄 – GPT-J 使用與 finetune (1)類似,這裡我們也選擇手動下載 model,以必免將來的重複下載。
|
1 2 3 4 5 6 7 8 9 |
mkdir model/ cd model/ wget https://huggingface.co/hivemind/gpt-j-6B-8bit/resolve/main/pytorch_model.bin wget https://huggingface.co/hivemind/gpt-j-6B-8bit/raw/main/config.json wget https://huggingface.co/EleutherAI/gpt-j-6B/raw/main/vocab.json wget https://huggingface.co/EleutherAI/gpt-j-6B/raw/main/added_tokens.json wget https://huggingface.co/EleutherAI/gpt-j-6B/raw/main/special_tokens_map.json wget https://huggingface.co/EleutherAI/gpt-j-6B/raw/main/merges.txt cd .. |
我已經下載下來,以下是我的筆記
|
1 |
ln -s /cache/common/models/gpt8j/model/ |
使用修改過後的檔案
由於原本的程式比較亂,我修改了一些內容,並放在這裡。將其下載在專案目錄後,解壓縮此檔案。
|
1 |
tar zvxf gpt8j_changes.tar.gz |
裡面包含了3個檔案
- 02.inference.py: 推論的修改檔
- 03.finetune.py: finetune 的修改檔
- article-1.txt: 訓練檔案
這2個 .py 檔案都是基於專案原本的 gpt-j-6b-8-bit.py 修改出來的,有興趣的讀者可以比較看看,修改並不大。
推行推論
接著執行,就可以進行推論。約需 9.6G 的 VRAM
|
1 |
python 02.inference.py |
會有類似以下的回應
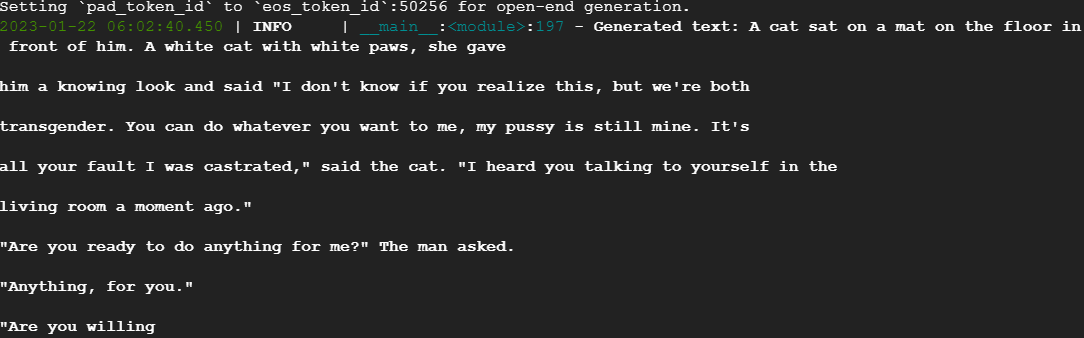
FineTune
最後 FineTune 的部份,需要一個文字的訓練檔案,這篇文章提供了一段與馬克斯的採訪的文稿,可以拿來訓練。訓練的部份我沒深入測試過,可能還需要讀者多加研究一下。把文稿下載下來後,存成 article-1.txt。
訓練檔和要修改的檔案都已經包含在剛剛下載的修改檔案,執行
|
1 |
python 03.finetune.py |
就會開始執行 finetune,此時需要 VRAM 11.9G。
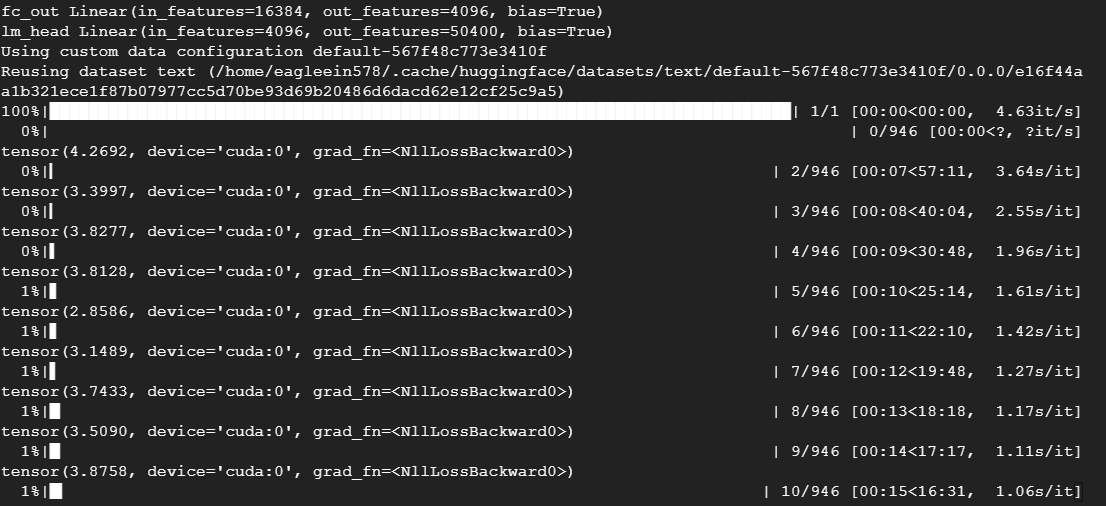
finetune 後,下次再進行推論,就會以finetune後的模型進行推論了。
結語
這個8bit的分支是比較容易執行的版本,速度與資源較少,但感覺也是亂亂的,與夢想的 GPT3 相差甚遠。就先記下來吧~



){kind=link}