前幾天研究的 ChatGLM2-6B,雖然不錯,但感覺出錯機率也不小,是屬於 better than nothing 的那種。他們其實還有12B的模型,但沒開放出來。不死心的情況下,逛來逛去讓我發現了這個百川模型(Baichuang2)。
才沒幾天前 (9月6日) 他們發佈了2代版本,剛好就讓我遇上了,感覺13B的版本比起來強大不少。不過 13B 的記憶體吃的很兇,所以連我的 RTX4090 都要降級才能跑
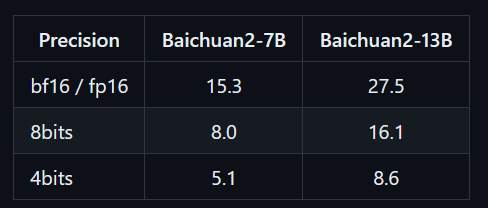
官方的說法是 4bits 只會影響準確率 1~2%。 我是使用8bit,大致感覺 ok,明顯比 chatGLM2-6B好。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 2 |
conda create -n baichuang python=3.9 conda activate baichuang |
源碼下載與安裝環境
安裝下面套件。
|
1 2 3 4 5 |
git clone https://github.com/baichuan-inc/Baichuan2 cd Baichuan2 pip install -r requirements.txt pip install scipy echo "conda activate baichuabg" > env.sh |
下載模型
|
1 2 3 4 |
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash sudo apt-get install git-lfs git clone https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat #git clone https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits |
下載完,可以把 .git 刪除,結省一些空間
|
1 |
rm -rf Baichuan2-13B-Chat/.git |
將模型轉化為8bit
由於 13B 所需的記憶體為 26G,已超過 RTX4090。所以需要將其降為 8bit 精度,以節省記憶體。具體的轉換腳本如下,若有需要4bit的版本,官方也有提供直接下載
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import json import torch import streamlit as st from transformers import AutoModelForCausalLM, AutoTokenizer from transformers.generation.utils import GenerationConfig @st.cache_resource def init_model(): print("before load") model = AutoModelForCausalLM.from_pretrained( "Baichuan2-13B-Chat", load_in_8bit=True, device_map="auto", trust_remote_code=True ) model.save_pretrained("Baichuan2-13B-Chat-int8") init_model() |
轉換後將 token 相關檔案複製過去
|
1 |
cp Baichuan2-13B-Chat/tokeniz* Baichuan2-13B-Chat-int8/ |
執行 Baichuan2-13B-Chat-int8 模型
修改 web_demo.py,將模型都改成 “Baichuan2-13B-Chat-int8”, 最後執行 streamlit run web_demo.py 就可以了
輸出繁體中文
由於是大陸訓練的模型,輸出都是簡體中文。可以透過 opencc 的即時轉換,將其改為繁體。修改的 diff 如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
--- Baichuan2/web_demo.py 2023-09-18 08:05:34.399034468 +0800 +++ baichuan.bak/Baichuan2/web_demo.py 2023-09-14 09:20:32.707657358 +0800 @@ -3,6 +3,8 @@ import streamlit as st from transformers import AutoModelForCausalLM, AutoTokenizer from transformers.generation.utils import GenerationConfig +from opencc import OpenCC +cc = OpenCC('s2t') st.set_page_config(page_title="Baichuan 2") @@ -59,13 +59,14 @@ with st.chat_message("assistant", avatar='? '): placeholder = st.empty() for response in model.chat(tokenizer, messages, stream=True): + response = cc.convert(response) placeholder.markdown(response) if torch.backends.mps.is_available(): torch.mps.empty_cache() messages.append({"role": "assistant", "content": response}) print(json.dumps(messages, ensure_ascii=False), flush=True) if __name__ == "__main__": |
固定簡中的部份,可參考共同操作內的 zhTW.sh 文件,做轉換。
結語
所謂的大力出奇蹟,沒有任何理由,參數比較多效果就比較好。


{kind=link}