有好一陣子沒研究 AI 了 (RTX 4090 哭哭),最主要的原因是搞不出來個什麼毛。自己訓練的 GPT2 效果一直很差,最受益的可能還是學到它的一點點精神吧。
昨天突然又想到來研究一下有沒有新東西,就找到了這個 ChatGLM2-6B 。從結果來論,這個比之前自己試的 GPT2 強太多了,很接近 chatGPT3。而且又是中國清大的研究,著重在雙語(中英文),我覺得蠻有看頭的。由於 openAI 太封閉,沒辦法自架。我覺得這個 GLM2 是一個很好的替代選擇。
其實它的母專案是 GLM-130B從名字上也看的出來前面的是60億參數,後面是1300億參數。這之中應該還有其它異,但我也不甚明瞭,先以使用為主吧。
chatGLM2-6B 提供了預訓練的資料,還可以自己 fineTune。另外也有結合langChain可以自行搭建自己知識庫,這個我也是剛剛接觸。所以先從單純的 chatGLM2 入手。
之所以急著寫這些還未研究透徹的東西,是發現一陣子沒用,Torch 都跑到 2.0 版了,有些之前研究的東西,套件又不相容了,要指定版本才行。看來還是要用能吃 GPU的 docker 才能保証一致性,不要後來都無法重現成果了。雖然比較吃空間,但也是比較好的辦法了。
參考來源
本文是參考 LangChain + ChatGLM2-6B 搭建个人专属知识库 的前半部份(也就是不含 langChain)的部份,包含了 ChatGLM2-6B的安裝使用與微調。有 ChatGLM2 就代表有 ChatGLM1,不過我們就只用新的,不管舊的了。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 2 |
conda create -n chatglm2 python=3.9 conda activate chatglm2 |
源碼下載與安裝環境
安裝下面套件。
|
1 2 3 4 |
git clone https://github.com/THUDM/ChatGLM2-6B cd ChatGLM2-6B pip install -r requirements.txt echo "conda activate chatglm2" > env.sh |
下載模型
|
1 |
git clone https://huggingface.co/THUDM/chatglm2-6b |
這個模型有 12GB,請耐心等候。
修改程式
這邊我們會修改程式來指定模型的位置,與 WEB 要監聽的IP。編輯 web_demo.py
|
1 2 3 4 5 6 7 |
# 因为前面改了模型默认下载地址,所以这里需要改下路径参数 # 修改 web_demo.py 文件 tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b", trust_remote_code=True) model = AutoModel.from_pretrained("chatglm2-6b", trust_remote_code=True).cuda() # 如果想要本地访问,需要修改此处 demo.queue().launch(share=True, inbrowser=True, server_name='0.0.0.0', server_port=7860) |
修改完後,就可以啟動程式
|
1 |
python web_ui.py |
打開瀏覽器訪問 IP:7860 就可以如 chatGPT 一樣詢問問題了!
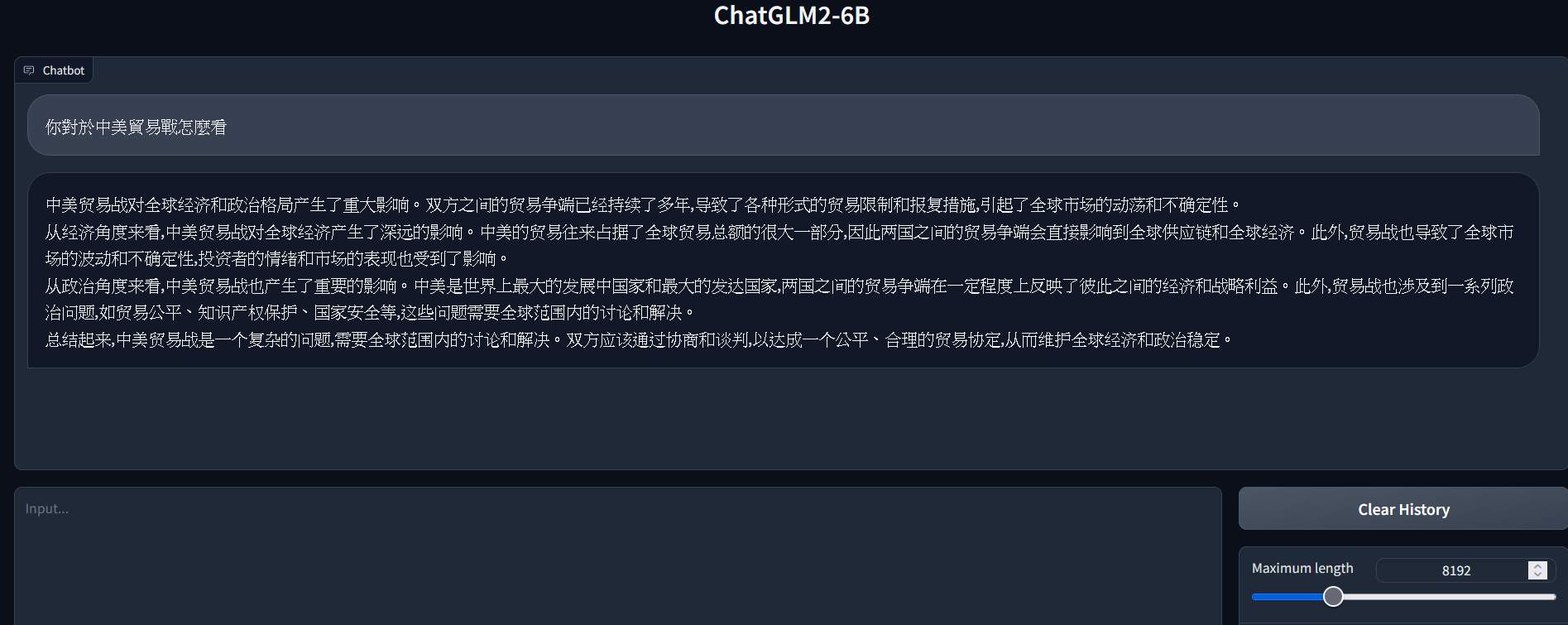
問個問題吧
你也可以用另一個方式啟動伺服器,但結果會稍有不同。此法仍需修改一下原始碼,從本地載入模型。
|
1 |
streamlit run web_demo2.py |

streamlit 結果
基于 P-Tuning 微调 ChatGLM2-6B
P-Tuning 是官方的微調方案。首先安裝套件
|
1 2 |
pip install transformers==4.27.1 pip install rouge_chinese nltk jieba datasets |
停用 W&B
|
1 |
export WANDB_DISABLED=true |
進入 ptuning 目錄,分別建立 train.json 與 dev.json 這兩個檔案
|
1 2 3 4 5 |
{"content": "你好,你是誰", "summary": "你好,我是樹先生的助手小6。"} {"content": "你是誰", "summary": "你好,我是樹先生的助手小6。"} {"content": "樹先生是誰", "summary": "樹先生是一個程式師,熱衷於用技術探索商業價值,持續努力為粉絲帶來價值輸出,運營公眾號《程式師樹先生》。"} {"content": "介紹下樹先生", "summary": "樹先生是一個程式師,熱衷於用技術探索商業價值,持續努力為粉絲帶來價值輸出,運營公眾號《程式師樹先生》。"} {"content": "樹先生", "summary": "樹先生是一個程式師,熱衷於用技術探索商業價值,持續努力為粉絲帶來價值輸出,運營公眾號《程式師樹先生》。"} |
修改 train.sh
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
PRE_SEQ_LEN=32 LR=2e-2 NUM_GPUS=1 torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \ --do_train \ --train_file train.json \ --validation_file dev.json \ --preprocessing_num_workers 10 \ --prompt_column content \ --response_column summary \ --overwrite_cache \ --model_name_or_path $PWD/../chatglm2-6b \ --output_dir $PWD/../output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \ --overwrite_output_dir \ --max_source_length 128 \ --max_target_length 128 \ --per_device_train_batch_size 1 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 16 \ --predict_with_generate \ --max_steps 1000 \ --logging_steps 10 \ --save_steps 1000 \ --learning_rate $LR \ --pre_seq_len $PRE_SEQ_LEN |
修改 evalution.sh
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
PRE_SEQ_LEN=32 CHECKPOINT=adgen-chatglm2-6b-pt-32-2e-2 STEP=1000 NUM_GPUS=1 torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \ --do_predict \ --validation_file dev.json \ --test_file dev.json \ --overwrite_cache \ --prompt_column content \ --response_column summary \ --model_name_or_path $PWD/../chatglm2-6b \ --ptuning_checkpoint $PWD/../output/$CHECKPOINT/checkpoint-$STEP \ --output_dir $PWD/../output/$CHECKPOINT \ --overwrite_output_dir \ --max_source_length 128 \ --max_target_length 128 \ --per_device_eval_batch_size 1 \ --predict_with_generate \ --pre_seq_len $PRE_SEQ_LEN |
然後分別執行訓練
|
1 |
bash train.sh |
與推理
|
1 |
bash evaluate.sh |
運行微調後結果
同樣在 ptuning 目錄下,修改 web_demo.sh
|
1 2 3 4 5 6 |
PRE_SEQ_LEN=32 CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \ --model_name_or_path $PWD/../chatglm2-6b \ --ptuning_checkpoint $PWD/../output/adgen-chatglm2-6b-pt-32-2e-2/checkpoint-1000 \ --pre_seq_len $PRE_SEQ_LEN |
將 web_demo.py 的接受網址也修改一下
|
1 |
demo.queue().launch(share=False, inbrowser=True, server_name='0.0.0.0', server_port=7860) |
最後再執行
|
1 |
bash web_dmeo.sh |
透過瀏覽器問一下誰是樹先生(也就是剛才微調的內容),就可以得到一些訊息。
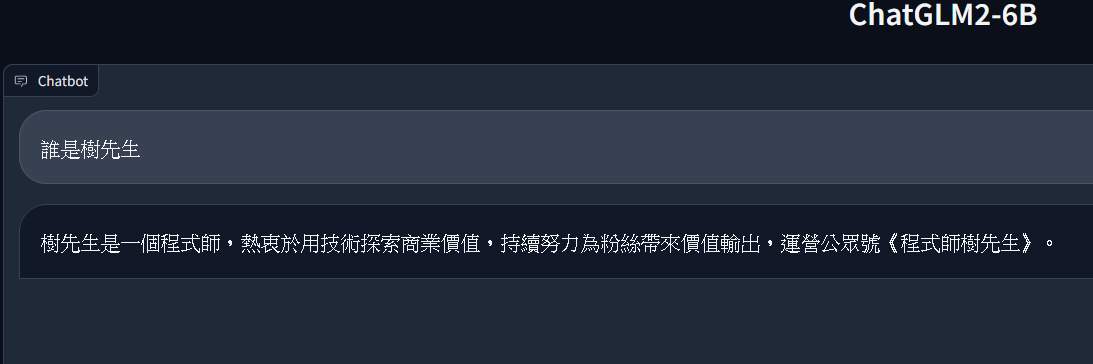
樹先生
量化
偶然的機會研究到怎麼量化成 4bit結省記憶體,大概佔用6G記憶體。安裝
|
1 |
pip install accelerate bitsandbytes |
以下面程式化來做量化,然後存檔。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from transformers import AutoModel, AutoTokenizer import gradio as gr import mdtex2html from utils import load_model_on_gpus import sys tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b", trust_remote_code=True) print("before load") model = AutoModel.from_pretrained("chatglm2-6b", trust_remote_code=True).quantize(4) print("before save") model.save_pretrained("chatglm2-6b-int4") print("after save") sys.exit(0) |
結語
這是一個比較偏向技術性的微調,花的時間也相對長。原作還有一個「知識庫」 的介紹,相對比較(短),我雖然用過但也還不確定其正確信。我還是相信慢一點的比較正確。下一篇就會介紹這個搭配 landChain + chatGLM2 的結合。



{kind=link}