在上一篇 AI 學習紀錄 – ChatGLM2-6B 使用與微調 裡,我們單獨的介紹 ChatGLM2 這個類 chatGPT 專案。而本文要介紹的是基於 ChatGLM2 (或其它聊天系統) 的LangChain-ChatChat個人知識管理庫。
![]()
它的特點是可以
- 快速在不同的聊天系統間切換,如 chatGPT 與 chatGLM 間
- 可以上傳文件,建立一個智能檢索系統。如法律、醫學之類的
可以建立自己的知識庫算是最大的優點,看起來的確有那個效果,不過還沒深入使用。因為檢索的有點太快,不像是一般的AI訓練,效果待觀查。
所需硬體
建議 16GB 以上顯卡,降規的話好像可以用6GB即可,但我沒試過。沒 GPU 跑的話,系統要32GB RAM才夠,但是速度很慢,i7-12700K大概可以每秒出來2個字吧。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 2 |
conda create -n langchat python=3.9 conda activate langchat |
源碼下載與安裝環境
安裝下面套件。
|
1 2 3 4 |
git clone https://github.com/chatchat-space/Langchain-Chatchat.git cd Langchain-Chatchat pip install -r requirements.txt echo "conda activate langchat" > env.sh |
下載模型與Embedding
由於 git 下載大檔,要支援 LFS。參考這篇文章的做法,可以安裝成功
|
1 2 |
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash sudo apt-get install git-lfs |
接著在下載模型與Embeddings
|
1 2 |
git clone https://huggingface.co/THUDM/chatglm2-6b git clone https://huggingface.co/moka-ai/m3e-base |
編輯設定檔
|
1 2 |
cp configs/server_config.py.example configs/server_config.py cp configs/model_config.py.example configs/model_config.py |
首先將範例設定檔複製一份。然後修改 model_config.py 和 server_config.py, 其 diff 差異如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
14c14,29 < "m3e-base": "m3e-base", --- > "ernie-tiny": "nghuyong/ernie-3.0-nano-zh", > "ernie-base": "nghuyong/ernie-3.0-base-zh", > "text2vec-base": "shibing624/text2vec-base-chinese", > "text2vec": "GanymedeNil/text2vec-large-chinese", > "text2vec-paraphrase": "shibing624/text2vec-base-chinese-paraphrase", > "text2vec-sentence": "shibing624/text2vec-base-chinese-sentence", > "text2vec-multilingual": "shibing624/text2vec-base-multilingual", > "text2vec-bge-large-chinese": "shibing624/text2vec-bge-large-chinese", > "m3e-small": "moka-ai/m3e-small", > "m3e-base": "moka-ai/m3e-base", > "m3e-large": "moka-ai/m3e-large", > "bge-small-zh": "BAAI/bge-small-zh", > "bge-base-zh": "BAAI/bge-base-zh", > "bge-large-zh": "BAAI/bge-large-zh", > "bge-large-zh-noinstruct": "BAAI/bge-large-zh-noinstruct", > "text-embedding-ada-002": os.environ.get("OPENAI_API_KEY") 23a39,44 > "chatglm-6b": { > "local_model_path": "THUDM/chatglm-6b", > "api_base_url": "http://localhost:8888/v1", # "name"修改為fastchat服務中的"api_base_url" > "api_key": "EMPTY" > }, > 25,28c46,86 < "local_model_path": "chatglm2-6b", < "api_base_url": "http://localhost:8888/v1", # "name"修改? FastChat 服?中的"api_base_url" < "api_key": "EMPTY" < }, --- > "local_model_path": "THUDM/chatglm2-6b", > "api_base_url": "http://localhost:8888/v1", # URL需要與運行fastchat服務端的server_config.FSCHAT_OPENAI_API一致 > "api_key": "EMPTY" > }, > > "chatglm2-6b-32k": { > "local_model_path": "THUDM/chatglm2-6b-32k", # "THUDM/chatglm2-6b-32k", > "api_base_url": "http://localhost:8888/v1", # "URL需要與運行fastchat服務端的server_config.FSCHAT_OPENAI_API一致 > "api_key": "EMPTY" > }, > > # 調用chatgpt時如果報出: urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='api.openai.com', port=443): > # Max retries exceeded with url: /v1/chat/completions > # 則需要將urllib3版本修改為1.25.11 > # 如果依然報urllib3.exceptions.MaxRetryError: HTTPSConnectionPool,則將https改為http > # 參考https://zhuanlan.zhihu.com/p/350015032 > > # 如果報出:raise NewConnectionError( > # urllib3.exceptions.NewConnectionError: <urllib3.connection.HTTPSConnection object at 0x000001FE4BDB85E0>: > # Failed to establish a new connection: [WinError 10060] > # 則是因為內地和香港的IP都被OPENAI封了,需要切換為日本、新加坡等地 > > # 如果出現WARNING: Retrying langchain.chat_models.openai.acompletion_with_retry.<locals>._completion_with_retry in > # 4.0 seconds as it raised APIConnectionError: Error communicating with OpenAI. > # 需要添加代理訪問(正常開的代理軟件可能會攔截不上)需要設置配置openai_proxy 或者 使用環境遍歷OPENAI_PROXY 進行設置 > # 比如: "openai_proxy": 'http://127.0.0.1:4780' > "gpt-3.5-turbo": { > "api_base_url": "https://api.openai.com/v1", > "api_key": os.environ.get("OPENAI_API_KEY"), > "openai_proxy": os.environ.get("OPENAI_PROXY") > }, > # 線上模型。當前支持智譜AI。 > # 如果沒有設置有效的local_model_path,則認為是在?模型API。 > # 請在server_config中為每個在?API設置不同的連接埠 > # 具體註冊及api key獲取請前往 http://open.bigmodel.cn > "chatglm-api": { > "api_base_url": "http://127.0.0.1:8888/v1", > "api_key": os.environ.get("ZHIPUAI_API_KEY"), > "provider": "ChatGLMWorker", > "version": "chatglm_pro", # 可選包括 "chatglm_lite", "chatglm_std", "chatglm_pro" > }, |
|
1 2 3 4 |
16c16 < "host": "0.0.0.0", --- > "host": DEFAULT_BIND_HOST, |
DIFF檔看起來有點亂。model_config.py 在embedding_model_dict只保留了m3e-base, llm_model_dict只保留了chatglm2-6b。而 server_config.py 則是允許從外部機器連進來。
初始化與啟動
下達命令來進行知識庫的初始化
|
1 |
python init_database.py --recreate-vs |
然後用一鍵啟動來執行所有服務
|
1 |
python startup.py -a |
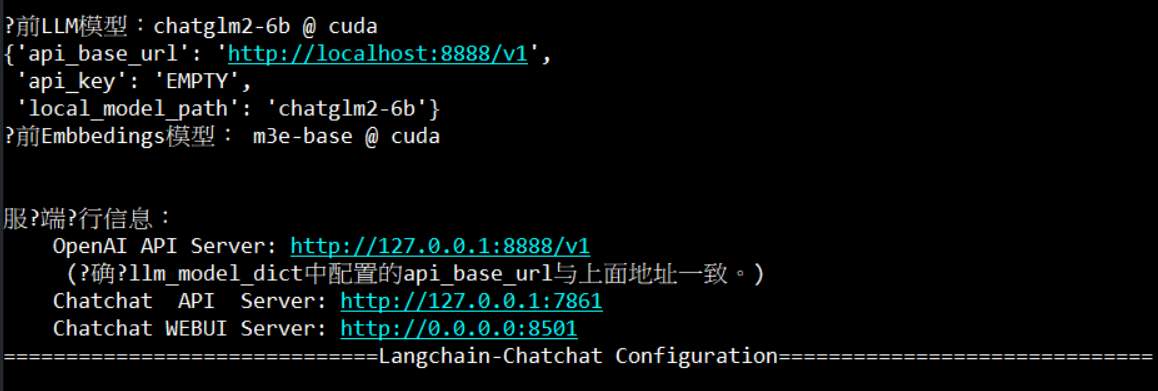
啟動
看到上面畫面就算啟動成功了,接下來就用瀏覽器來連上網頁, http://IP:8501 了。
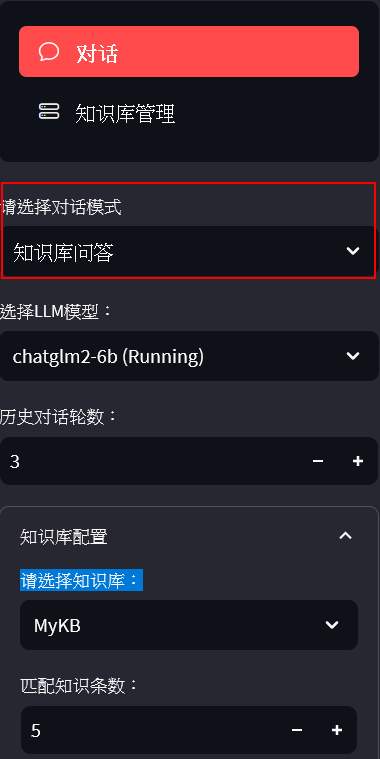
首頁
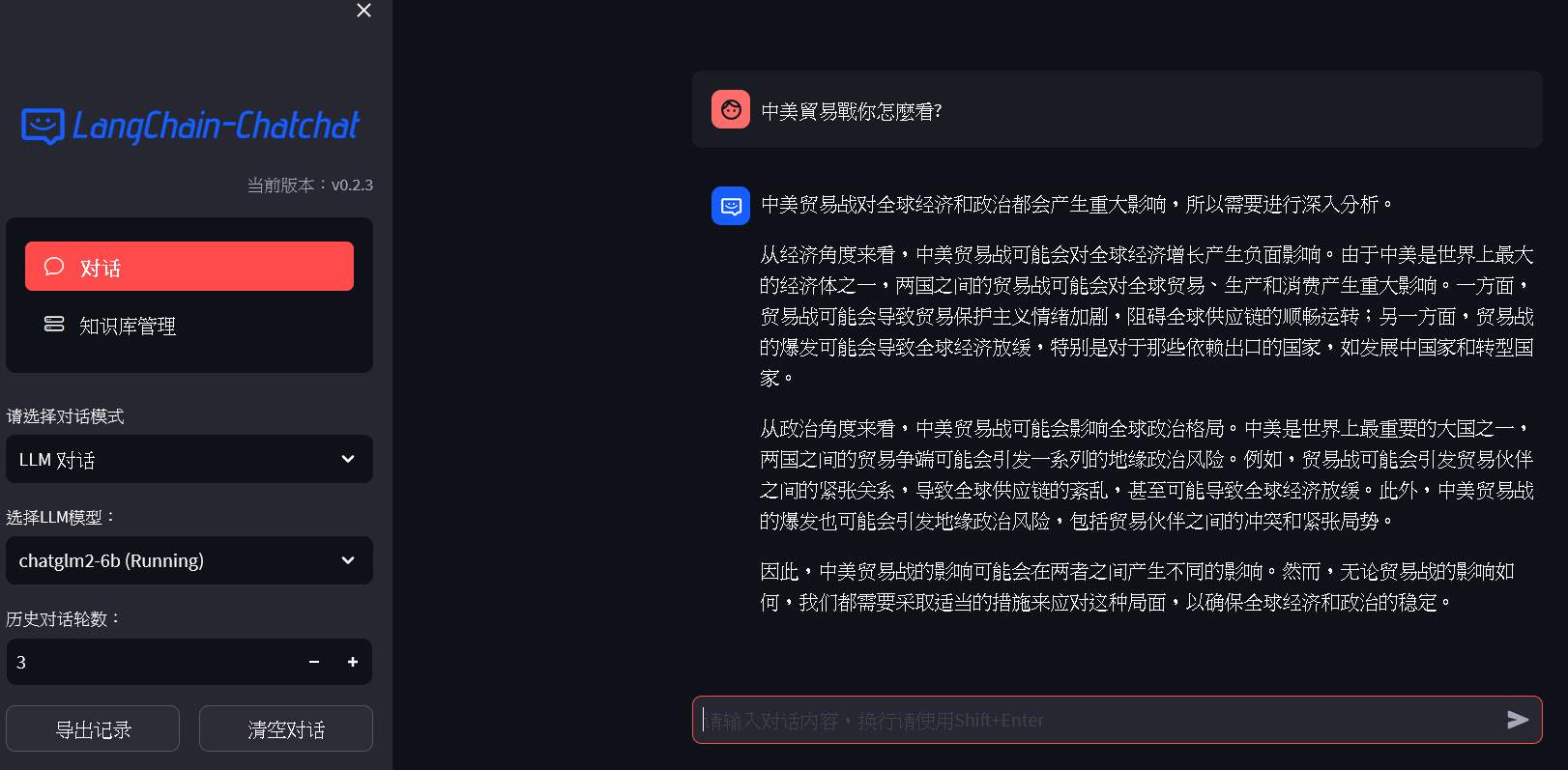
左邊可以選擇要使用對話的方式,包含LLM對話(就像chatGPT), 知識庫問答或搜索引擎。歷史對話輪數,則是他會參考之前的問答個數。右邊則是問答區。
知識庫管理
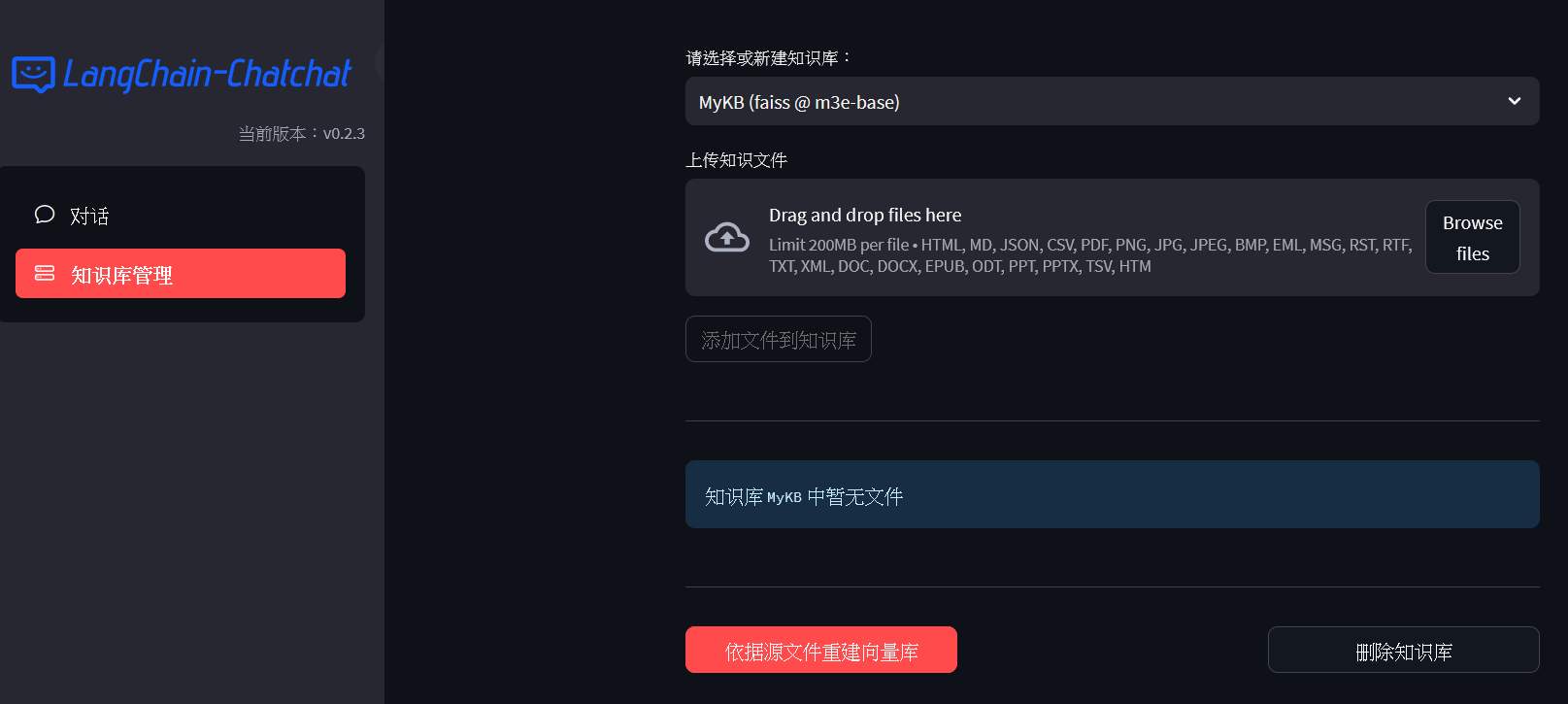
進入知識庫管理,可以建立和上傳檔案等管理動作,我們從法務部下載著作權法下來試試看,下載 PDF 就可以。
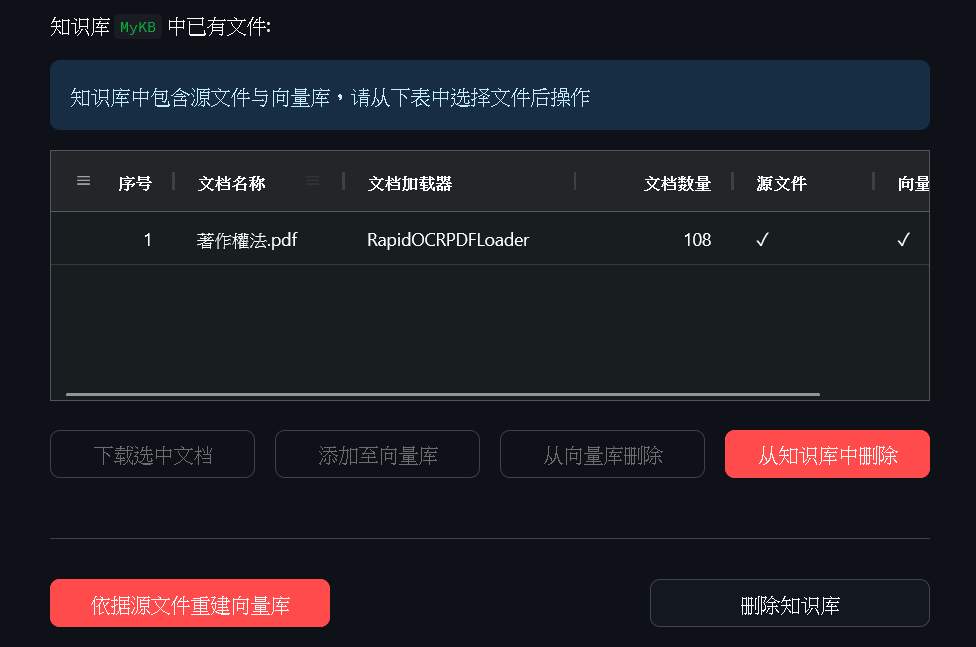
接下來切回對話,選擇知識庫問答。
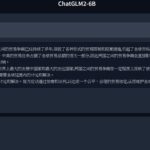
我問了一下「散佈盜版軟體要會被罰嗎」「刑期範圍為何?」,看他講的都頭頭是道。我認真看了一條,還真的是對的!


「違反第八十條之一規定,可能被處一年以下有期徒刑、拘役或科或併科新臺幣二萬元以上二十五萬元以下罰金」
|
1 2 3 4 5 6 7 8 9 10 |
第 80-1 條 著作權人所為之權利管理電子資訊,不得移除或變更。但有下列情形之一者,不在此限: 一、因行為時之技術限制,非移除或變更著作權利管理電子資訊即不能合法利用該著作。 二、錄製或傳輸系統轉換時,其轉換技術上必要之移除或變更。 明知著作權利管理電子資訊,業經非法移除或變更者,不得散布或意圖散布而輸入或持有該著作原件或其重製物,亦不得公開播送、公開演出或公開傳輸。 第 96-1 條 有下列情形之一者,處一年以下有期徒刑、拘役,或科或併科新臺幣二萬元以上二十五萬元以下罰金: 一、違反第八十條之一規定者。 二、違反第八十條之二第二項規定者。 |
結語
這2篇真是刷了我一波觀念,離上次研究才過沒多久,已經有可以拿到私用的強大檢索器了!AI進步真的很快啊~



{kind=link}