接著上一篇的AI 學習紀錄 – 單步GPT推論, 網頁架設 (1),接下來就是做單步推論了。單步推論所需要安裝的東西,差不多跟完整的訓練差不多。所以還是 follow 之前的 AI 學習文章,儘量提供完整的步驟。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 |
conda create -n single_infer python=3.9 |
建立專案目錄
使用下面的命令,將專案下載(如附件)下來,並建立環境切換檔。
|
1 2 3 4 5 6 7 8 |
cd projects wget https://moon-half.info/wp-content/uploads/2023/06/single_infer.tar.gz tar zvxf single_infer.tar.gz cd single_infer echo "conda activate single_infer" > env.sh echo 'export LD_LIBRARY_PATH=$HOME/anaconda3/envs/paddle/lib/:$LD_LIBRARY_PATH' >> env.sh source ./env.sh sed -i 's/a.py/single_infer.py/g' run |
其中的一個目錄 tokenizations 是由 GPT2-Chinese 專案(https://github.com/Morizeyao/GPT2-Chinese.git)借用過來的。
安裝套件
執行下列命令來安裝所需套件
|
1 |
pip install -r requirements.txt |
執行程式
下達以下命令,來看每一步的選詞。這一步會下載 huggingface 的 gpt2-large 模型,第一次會比較久 (約3GB)。
|
1 |
source ./run |
主程式 single_infer.py 會推論 “A bartender is ” 後面的10句話,每次都選取機率最高的那個。其輸出整理前5個如下
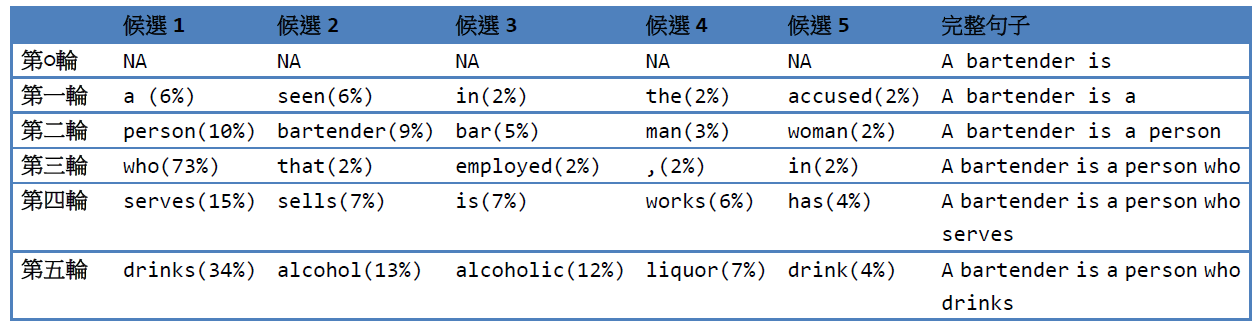
單步推論的機率
程式是選第一個(機率最高的),所以輸出總是固定的。若做出不同的選擇,就可以獲得不同的輸出。GPT 是以前文內容,來推測下一個字的機率,但符不符合文法或現實的用法,則不是它能判斷的。若要有更好的推論,則應該會引如其它的選擇機制,我想這也是各 AI 大廠的獨門秘技吧。
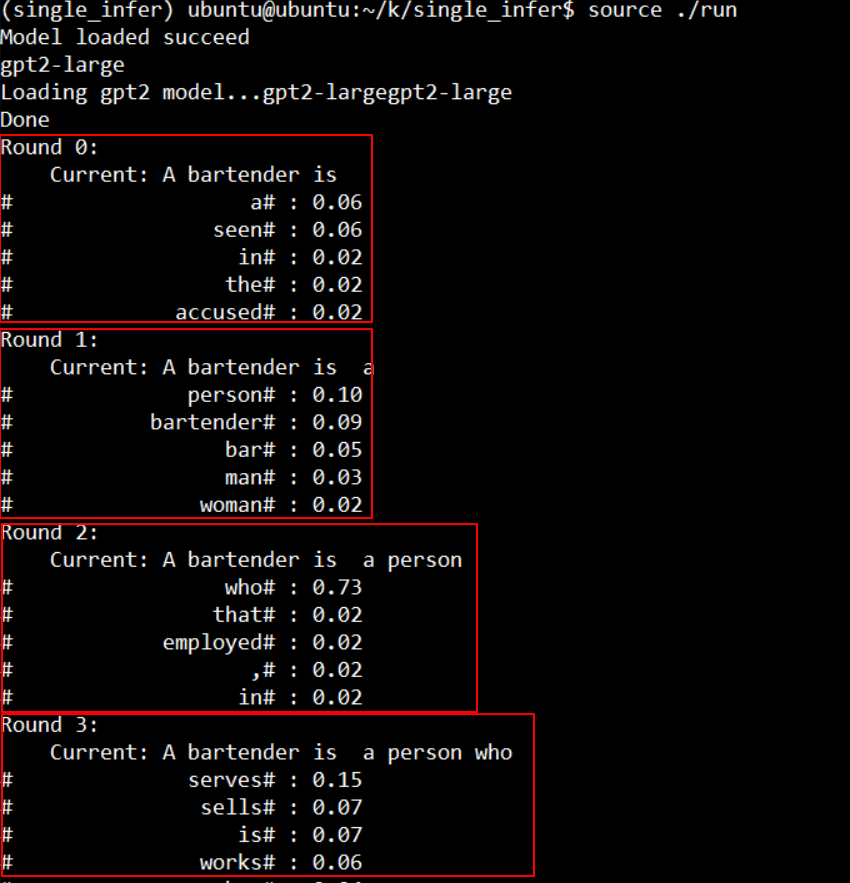
程式輸出
程式碼解析
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
# -*- coding: utf-8 -*- # vim: expandtab import torch from transformers import GPT2Tokenizer from transformers import GPT2LMHeadModel import tokenizers import random import sys import time from tokenizations import tokenization_bert_word_level as tokenization_bert import argparse if torch.cuda.is_available(): device="cuda" else: device="cpu" device="cpu" def choose_token(token_list): for i in range(len(token_list)): if token_list[i].item() == 4: continue return token_list[i].item() def token_to_text(tokenizer, id): return tokenizer.decode(id) def select_top_k(predictions, k=10): global tokenizer last=len(predictions)-1 if last < 0: print("Error, prediction is 0") sys.exit(0) sorted_p = torch.softmax(predictions[last].sort(descending=True)[0],0) sorted_i = predictions[last].sort(descending=True)[1][:k] return sorted_i, sorted_p def infer(msg, k=5): total_predicted_text = msg indexed_tokens = tokenizer.encode(total_predicted_text) #print(indexed_tokens) tokens_tensor = torch.tensor(indexed_tokens).to(device) with torch.no_grad(): outputs = model(input_ids=tokens_tensor) predictions = outputs[0] return select_top_k(predictions, k) parser = argparse.ArgumentParser() parser.add_argument('--model', default='', type=str, required=True, help='') parser.add_argument('--vocab', default='', type=str, required=True, help='') parser.add_argument('--vocab_type', default="bert", type=str, required=True, help='') args = parser.parse_args() print(args.vocab) if args.vocab_type == "gpt2": tokenizer = GPT2Tokenizer.from_pretrained(args.vocab) else: tokenizer = tokenization_bert.BertTokenizer(vocab_file=args.vocab) print("Loading gpt2 model..." + args.model, end="") #model = GPT2LMHeadModel.from_pretrained('gpt2') print(args.model) model = GPT2LMHeadModel.from_pretrained(args.model).to(device) model.eval() print("Done") text = "A bartender is " ts=time.time() for i in range(10): idx,prob = infer(text, k=5) print("Round " + str(i) + ":") print(" Current: " + text) for j in range(len(idx)): print("#%20s# : %.2f" % (token_to_text(tokenizer, idx[j].item()).replace(" ", ""), prob[j].item())) text += token_to_text(tokenizer, choose_token(idx)) print(text) te=time.time() print("%.5f sec" % (te-ts)) |
L14~18: 由於單純的推論比較快,可以不用使用 GPU,這邊僅在 CPU 執行推論。這樣另外的好處是可以進行多個不同模型的推論,畢境系統的RAM還是遠多於顯卡的。
L54~58: 指定要使用的模型、字典與字典類型。這裡是使用huggingface的預訓練模型,分別是 “gpt2-large”, “gpt2-large” 與 “gpt2″。
L61~64: 載入字典檔以並建構分詞器。
L68: 載入模型,以使用訓練好的資料
L77~83: 推論下一個字詞,並將推論的字詞加入原文,進行下一次推論
最關鍵的部份在於 L77~83 這部份。其中 token_to_text() 行83, 最後呼叫的是 tokenizer.decode() 將一個 token ID (數字) 轉換為文字。而由於取到的是數個 ID (依機率排列),其中有可能是一些符號,所以我們濾掉了ID 4(好像是換行或空白)。
而推論的部份是行78的 infer()。 infer() 會推論文字 text 下一個字詞的5個候選字,並且依機率排序。並將之存在 idx (token index)與prob(機率)。
infer() 最先會將一串文字轉換為一個一個的 token ID,也就是字詞所代表的ID。而至於有幾個ID,取決於所使用的 tokenizer分詞器,簡單的就用字,難一點的就用詞,這邊我們就用gpt2提供的,就不煩腦這些了。取得這些 token ID 後,將之丟入模型內去推測下一個字詞。
|
1 2 3 |
with torch.no_grad(): outputs = model(input_ids=tokens_tensor) predictions = outputs[0] |
predictions 取得的是所有字詞用於下一個字的機率, 其是從 outputs[0] 取得的。至於 outputs[1:] 後是什麼,沒仔細研究。接著我們呼叫了另一個函式 select_top_k(),來取得前5個最可能的機率與其所代表的 token ID。
|
1 2 3 4 5 6 7 8 9 10 |
def select_top_k(predictions, k=10): global tokenizer last=len(predictions)-1 if last < 0: print("Error, prediction is 0") sys.exit(0) sorted_p = torch.softmax(predictions[last].sort(descending=True)[0],0) sorted_i = predictions[last].sort(descending=True)[1][:k] return sorted_i, sorted_p |
其實 prediction 是表達了原文中的第一個到最後一個字詞的下一個字的機率。而這邊我們是要推論最後一個字的下一字,所以只要看最後一個就行了(上圖行3)。
我們將最後一個字詞的 prediction 進行排序,就可以將機率最高的排在前面,進而就可以形成機率與其所代表的tokenID變數, sorted_p與sorted_i。機率的部份,先將 predictions[last]先進行排序,取得[0] (機率權重)進行 softmax,轉成機率。而字詞的部份,則是將predictions[last] 排序後取得[1](字詞 ID), 並只有前k個。
取得每個字詞的機率與ID後,自然就可以決定下個字了。在行 79~83,我們將推論的機率印出來,並將最高機率的字加入原文再進行推論。這樣就可以觀察中間的結果與最終的文字。
推論概觀
以下是個人推論,未必正確囉~
所謂的 tokenizer 就是一個分詞的功能,再將一個數字代表一個字詞,然後用於模型當中。所以模型與tokenizer是密不可分的,訓練後就不可提換。因為這個字詞的 ID 在另一個 tokenizer 中所代表的字詞又會不同。可以在原本的 tokenizer 最後加上新的,因為這不會影響既有的 ID 所代表的字。
由上述可知,tokenizer 也是一門學問,可能跟各種語言或所要求的實體資源有關。通常與訓練過程的資料有關,以中文為例。可以簡單的以”字”為單位,或以詞為單位。以詞為單位,可以推論出更符合語言的內容,但組合也更多。
tokenizer 的產生是一個步驟,而模型的訓練又是另外一個。tokenizer 是在建立所有可能出現的字詞,所以至少要包含單字,不然在訓練時就會出現 [UNK] (unknown) 這種 ID。而模型的訓練在於建立不同字詞順序時,對於下一個字詞的推論的機率。
結語
對於 GPT 雖然有基本的認知,但過一陣子又會忘了。基本使用不難,而進階的使用才是決勝關鍵吧!


){kind=link}