目前的語言大模型都有搭配的 http API, 像在這篇裡提到的 Langchat-chatcat 的 API。使用上算不上複雜,但想要使用時要下的參數好像就有點多。其實要搭建自己的 LLM API,就是在 http server 內接收一個 POST 或 GET 的要求,再透過 LLM 的 chat API 取得回應後,返回給 http 即可。
這種自建的方式感覺比較好客制化一點,當然是我自己不熟官方API的可能性也很大。
要訂制這種服務,其實就是把一般 CLI 的範例,再加上 Python HTTP 功能即可。這邊以通義千問 (Qwen) 為例,來紀錄一下這自己的程式碼。
LLM API 程式
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
# -*- coding: utf-8 -*- import os import sys import time from transformers import AutoModelForCausalLM, AutoTokenizer from transformers.generation import GenerationConfig from http.server import BaseHTTPRequestHandler, HTTPServer import logging from urllib.parse import unquote DEFAULT_CKPT_PATH = 'Qwen-14B-Chat-Int4' from opencc import OpenCC s2t = OpenCC('s2t') t2s = OpenCC('t2s') seed=0 class S(BaseHTTPRequestHandler): def _set_response(self): self.send_response(200) self.send_header('Content-type', 'text/plain; charset=utf-8') self.end_headers() def do_GET(self): self._set_response() i = self.path.find("?q=") if i == -1: logging.info("No GET content") self.wfile.write("Use '/?q=' to ask question".encode('utf-8')) else: url = self.path[i+3:] url = unquote(url) logging.info(url) q = t2s.convert(url) r = ask(q, config) r = s2t.convert(r) self.wfile.write(r.encode('utf-8')) def do_POST(self): content_length = int(self.headers['Content-Length']) # <--- Gets the size of data post_data = self.rfile.read(content_length) # <--- Gets the data itself logging.info("POST request,\nPath: %s\nHeaders:\n%s\n\nBody:\n%s\n", str(self.path), str(self.headers), post_data.decode('utf-8')) self._set_response() post = post_data.decode('utf-8') post = t2s.convert(post) r = ask(post,config); r = s2t.convert(r) self.wfile.write(r.encode('utf-8')) def run(server_class=HTTPServer, handler_class=S, port=8080): logging.basicConfig(level=logging.INFO) server_address = ('', port) httpd = server_class(server_address, handler_class) logging.info('Starting httpd... http://0.0.0.0:' + str(port)+'\n') logging.info('example: http://127.0.0.1:8080/?q=who is Trump') try: httpd.serve_forever() except KeyboardInterrupt: pass httpd.server_close() logging.info('Stopping httpd...\n') def load_model_tokenizer(): tokenizer = AutoTokenizer.from_pretrained( DEFAULT_CKPT_PATH, trust_remote_code=True, resume_download=True, ) device_map = "auto" model = AutoModelForCausalLM.from_pretrained( DEFAULT_CKPT_PATH, device_map=device_map, trust_remote_code=True, resume_download=True, ).eval() config = GenerationConfig.from_pretrained( DEFAULT_CKPT_PATH, trust_remote_code=True, resume_download=True, ) return model, tokenizer, config def ask(query, config): history = [] response, history = model.chat(tokenizer, query, history=history, generation_config=config, past_key_values=None) return response model, tokenizer, config = load_model_tokenizer() run() |
語言模型相關的 function 為
- load_model_tokenizer(), ask(): 前者載入模型, 後者以 chat API 取得對話回應
HTTP 相關的 function 為
- class S,run(): 前者為 http server 的基礎類,裡面做了GET / POST 的處理. run() 為啟動服務。
將上面的內容存檔,啟動後可以在 port 8080 做連接。
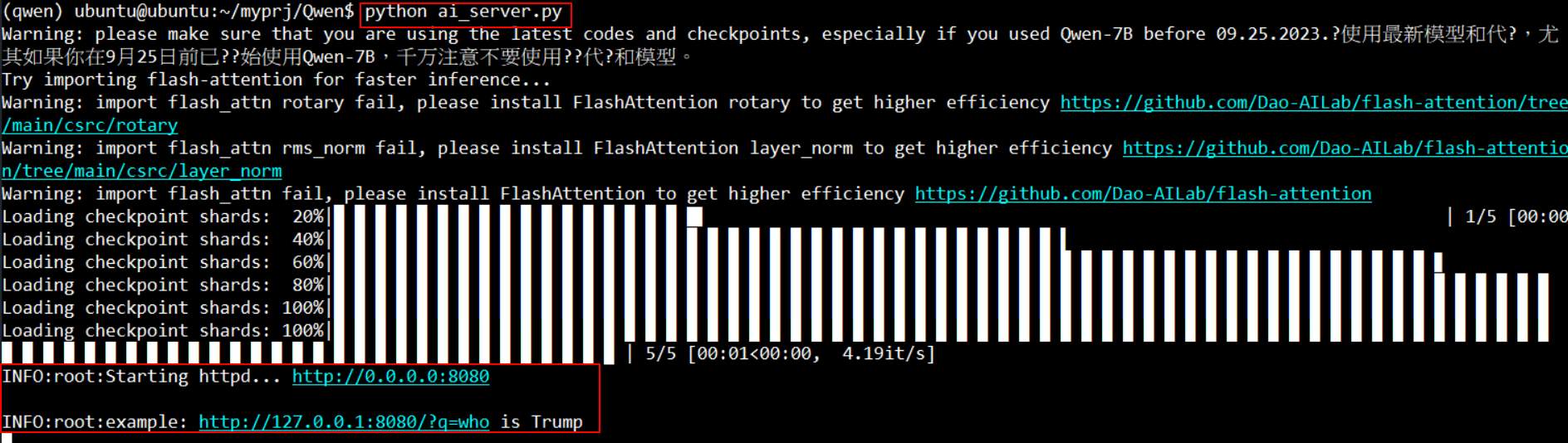
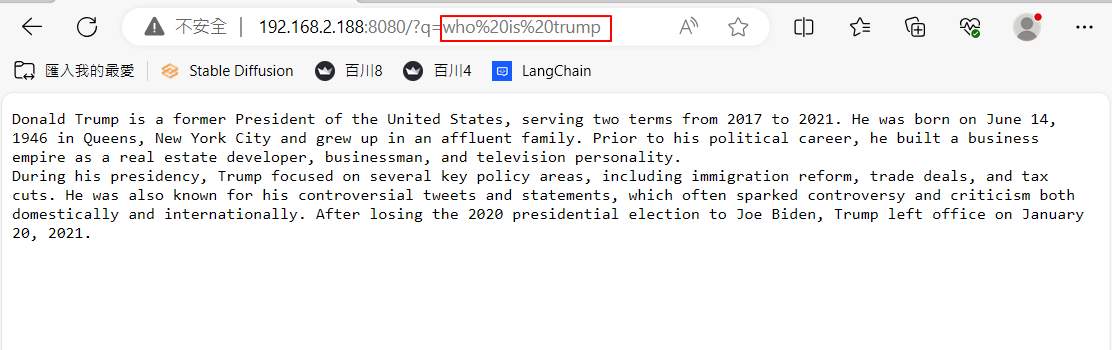
使用 GET 問答的話,只要在瀏覽器最後面加上 “/?q=” 再接上問題就行了. 下面是詢問”who is Trump”的回答, 中間的%20是瀏覽器自己補的。
要用 POST 話,使用一個 shell script 搭上 curl 可以完成簡單的任務。
|
1 2 3 4 |
#!/bin/bash Q="$1" curl -d "$Q" -H "Content-Type: application/x-www-form-urlencoded" -X POST http://localhost:8080/ echo "" |

結語
自建 API 的好處是可以客制化一些關鍵字來達到特殊的功能,例如啟動或關閉歷史功能、或者是即時抓取網路資料,雖然不怎麼聰明,但確實是比較實用。


{kind=link}