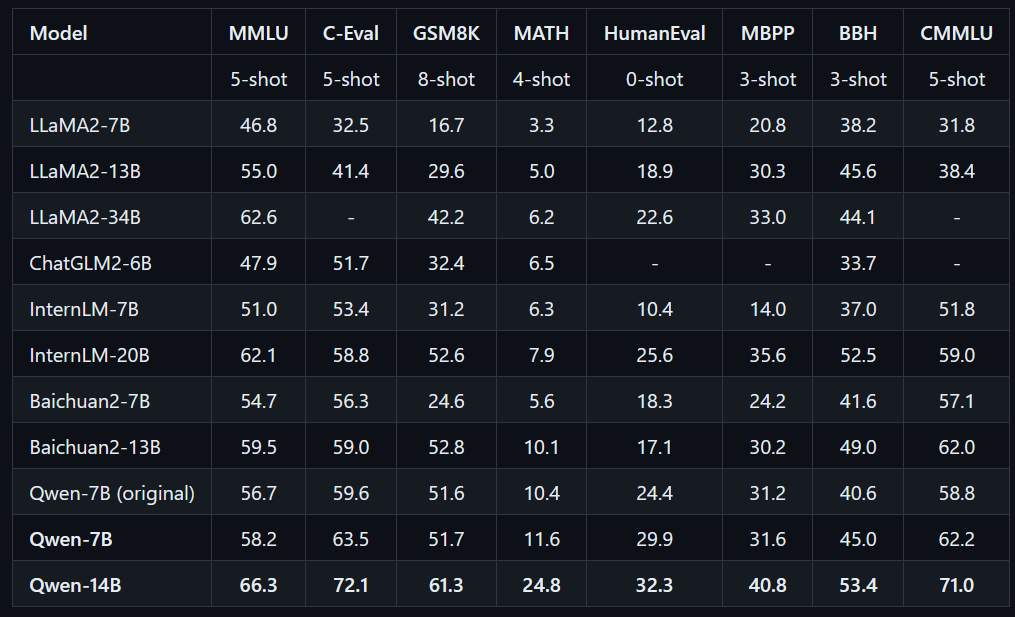
試用過的大語言模型也有好幾個了,包含 chatGLM2, Baichuan2, Llama,最近又看到一個強大的阿里通義千問 (Qwen)。通義千問在官網實驗數據看的出來其表現(Qwen-14B的模型)普遍的好於其它開源模型。
在翻譯的比較上, 我使用 chatGLM2 翻出來的感覺是國中生的水準, 而 Qwen則更接近一般的寫作水準。當然模型大小有差距,這種比較不太公平,不過也是給大家做個參考。 結果可以看一下,chatGLM2 翻譯的文章,與 Qwen 翻譯的文章。
但僅是再來玩一個大語言模型好像有點老梗了,本文要透過Qwen來進行 WordPress 文章的自動翻譯與發表,真正的把 AI 轉換成生產力。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 2 |
conda create -n qwen python=3.8 conda activate qwen |
下載專案與模型
|
1 2 3 4 5 6 7 8 |
git clone https://github.com/QwenLM/Qwen cd Qwen echo "conda activate qwen" > env pip install -r requirements.txt pip install -r requirements_web_demo.txt pip install optimum auto-gptq OpenCC==1.1.0 BeautifulSoup4 sudo apt-get install tidy git clone https://huggingface.co/Qwen/Qwen-14B-Chat-Int4 |
這裡直接下載 Qwen-14B-Chat-Int4 的量化版本模型,檔案大小約 9G,實際跑起會佔到13G VRAM左右。
執行 WEB Demo
編輯 web_demo.py 這個檔案,找到下面這樣。把原本的模型路徑改成 “Qwen-14B-Chat-Int4″。
|
1 |
DEFAULT_CKPT_PATH = 'Qwen/Qwen-7B-Chat' |
然後執行下面命令
|
1 |
python web_demo.py --server-name 0.0.0.0 -c Qwen-14B-Chat-Int4 |
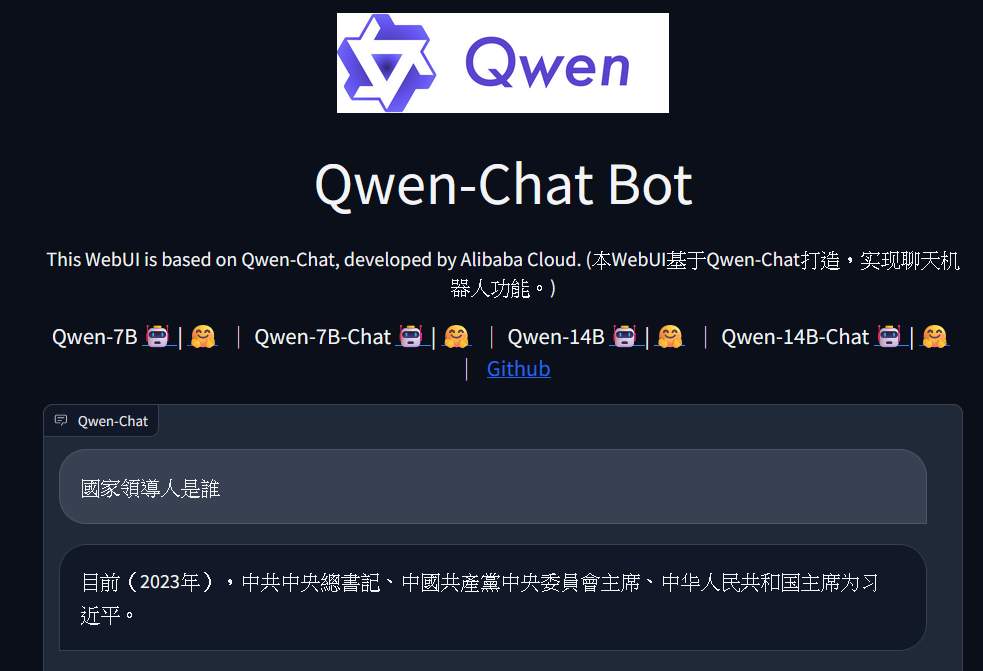
接著就可以用瀏覽器打開 http://IP:8000 來試用 web 的聊天介面。順便問了一個最近蠻紅的問題…. 跟人不一樣,一種米養出百種人。同樣的資料,會養出差不多模型~
WordPress 文章翻譯程式
要呼叫 Qwen 的對話功能,我從其範例 cli_demo.py 改寫了一下。其實目前大語言模型應用的關鍵 function 都蠻簡潔的,很多程式都是在優化使用者介面。下面就是我的翻譯程式
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 |
# -*- coding: utf-8 -*- import os import platform import shutil from copy import deepcopy import sys import re import time import torch from transformers import AutoModelForCausalLM, AutoTokenizer from transformers.generation import GenerationConfig from transformers.trainer_utils import set_seed import codecs from bs4 import BeautifulSoup DEFAULT_CKPT_PATH = 'Qwen-14B-Chat-Int4' from opencc import OpenCC s2t = OpenCC('s2t') t2s = OpenCC('t2s') seed=0 def has_chinese(msg): chset=re.compile('[\u4e00-\u9fff]+').findall(msg) if len(chset) == 0: return False return True def is_failed(src, rsp): invalid_keywords = [ "sorry", "Sorry", "抱歉", "請提供"] invalid_keywords = invalid_keywords +[ "translation incomplete", "<http", "Please provide"] for i in invalid_keywords: if rsp.find(i) != -1: set_seed(round(time.time())) return 1 if src.find("<a href=") != -1 and rsp.find("<a href=") == -1: set_seed(round(time.time())) return 1 return 0 def translate_retry(content): if has_chinese(content) == False: #print(f"tag {content} 沒有中文", file=sys.stderr) return content i=0 for i in range(20): rsp = translate(content, 0, config) #.replace("\n", "") if is_failed(content, rsp) == 1: continue break if i >= 19: print(f"翻譯失敗: {content} --> {rsp}", file=sys.stderr) rsp = content #sys.exit(1) #print(f"translate_tag {tag}: {match} --> \n{rsp}\n ", file=sys.stderr) content = content.replace(content, rsp) set_seed(seed) return content def translate_tag(content, tag): tag_name=tag pattern = rf'<{tag_name}>(.*?)</{tag_name}>' matches = re.findall(pattern, content, re.DOTALL) for match in matches: set_seed(seed) #match = match.replace("\n", "") if has_chinese(match) == False: continue i=0 for i in range(20): rsp = translate(match, 0, config) #.replace("\n", "") if is_failed(match, rsp) == 1: continue break if i >= 19: print(f"翻譯失敗: {match} --> {rsp}", file=sys.stderr) rsp = match #sys.exit(1) #print(f"translate_tag {tag}: {match} --> \n{rsp}\n ", file=sys.stderr) content = content.replace(match, rsp) set_seed(seed) return content def load_model_tokenizer(): tokenizer = AutoTokenizer.from_pretrained( DEFAULT_CKPT_PATH, trust_remote_code=True, resume_download=True, ) device_map = "auto" model = AutoModelForCausalLM.from_pretrained( DEFAULT_CKPT_PATH, device_map=device_map, trust_remote_code=True, resume_download=True, ).eval() config = GenerationConfig.from_pretrained( DEFAULT_CKPT_PATH, trust_remote_code=True, resume_download=True, ) return model, tokenizer, config def translate(query, i, config): history = [] if i == 199: query = f"這句話「{query}」的英文翻譯是什麼.\n\n" prepend="" else: prepend = '把下面的中文內容翻譯成英文, 不要有額外的說明.\n\n' response, history = model.chat(tokenizer, prepend+query, history=history, generation_config=config, past_key_values=None) all = " " + response+ " " return all model, tokenizer, config = load_model_tokenizer() f = codecs.open(sys.argv[1], "r", "UTF-8") in_pre = False while True: line = f.readline() if len(line) == 0: break line = line.replace("\n", "") if line.find("<pre") != -1: in_pre = True print(line) if line.find("</pre") != -1: in_pre = False continue if line.find("</pre") != -1: print(line) in_pre = False continue if in_pre == True: print(line) continue if line.find("ul>") != -1: print(line) continue if line.find("<li>") != -1: line = translate_tag(line, "li") print(line) continue if line.find("<h3>") != -1: line = translate_tag(line, "h3").replace(".", "") print(line) continue if line.find("<h4>") != -1: line = translate_tag(line, "h4").replace(".", "") print(line) continue if line.find("<h5>") != -1: line = translate_tag(line, "h5").replace(".", "") print(line) continue rsp = translate_retry(line) if is_failed(line, rsp) == 1: print("失敗: " + line + "--->" + rsp, file=sys.stderr) print(rsp) f.close() sys.exit(0) |
先說明一下 function
- has_chinese(): 檢查是否有中文, 有些很簡短的字句,若沒中文就對要翻譯了.
- is_failed(): 判斷翻譯是否失敗。由於 AI 翻譯具有一些隨機性,例如會答非所問或關鍵部份被刪掉。就要先判定一下再決定是否採用其輸出的結果,這個 function 跟你所使用的模型關係很大,若採用不同的LLM模型,錯誤型式可能就會不同。
- translate_retry(): 翻譯時會逐行處理,若沒有發現一些指定的 html tag 就會呼叫此 function 來做翻譯。所謂的 retry 就是在每次翻譯後,都會用 is_failed() 檢查一下,若失敗超過20次,就會用原文輸出。
- translate_tag(): 取出指定 tag 的內容來做翻譯,目前是用在標題(h)和列表(ui)
- load_model_tokenizer(): 從 cli 範例抓過來的,就是載入模型
- translate(): 呼叫模型進行翻譯。
簡要說明一下運作流程:
- 先載入模型然後讀取要翻譯的檔案做逐行處理。
- 如果有發現 pre 的標簽,就直接輸出,因為這是 wordpress 用來輸出原格式的標記。為避免對其中內容做翻譯,所以夾在中間的內容一律原樣輸出。
- 有發現 ul tag 就直接輸出
- 若發現 li tag 的話,會對中間的內容做翻譯
- 其它 h3~h5,也是對中間的內容做翻譯
- 其它的內容就都做翻譯
進行翻譯
典型的執行指令如下
|
1 |
python ai_translate_new.py article.txt > all.html |
其中 ai_translate_new.py 就是上面的程式,而 article.txt 則是 wordpress 的文章原始內容。其內容可以在 wordpress 的編譯器內看到,將其存成 article.txt。
由於我的 wordpress 是比較舊版了,也沒打算升級新的,所以用文章內常出現的 tag 都是很簡單的。新版的 wordpress 似忽有更好用的即視編輯工具,但這種工具通常會加很多 tag,會導致 AI 翻譯變得容易出錯。若你沒有翻成英文的需求,用新的工具就無妨,或者要對你的翻譯程式有更多的例外處理了。
執行翻譯程式中,若有失敗,也會顯示錯誤的字句。最後的內容,會被導到一個 all.html 內,以供檢示。

上面就是翻譯不出來的訊息,會印出原始訊息,和翻譯出的訊息。由於在 is_failed() 裡,我設置了不允許超連結不見的規則,所以就被判定成失敗了。翻譯失敗並不會有嚴重的影響,只是做為調整翻譯程的一個參考。失敗的情況下,原文會直接被加到最後結果內,就是要再自己翻譯一下而已。
翻譯完後,可以先檢查一下有沒有 html 的異常,這裡使用到了 tidy 這個工具。
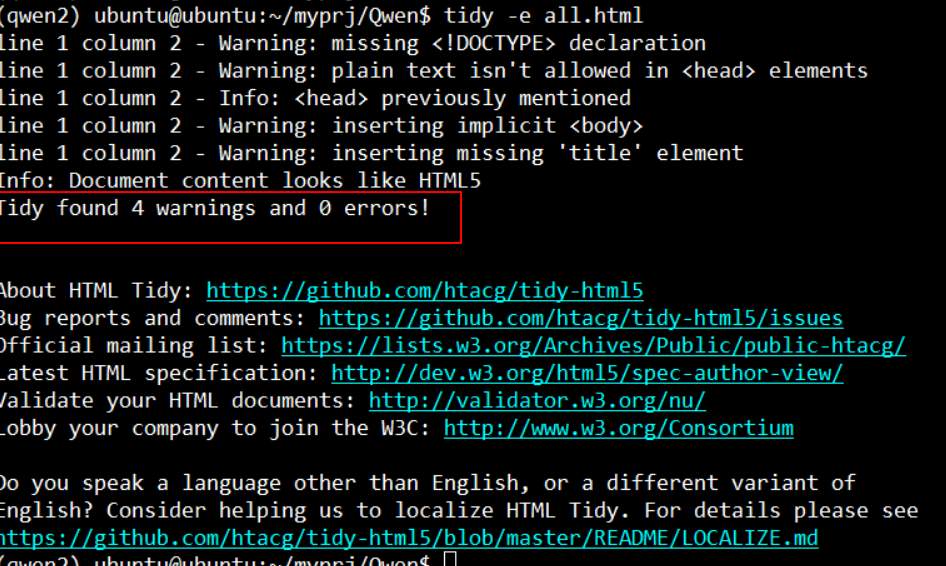
透過這個工具的 error 數,可以大概瞭解一下有無重大錯誤。有的話,其會列出錯誤的行數。這時可以透過修改 ai_translate_new.py 的 is_failed() 的規則來優化自動化程序,或乾脆手動修正也可以。
透過 tidy 的基本檢查後,可以直接打開這個 all.html 來看一下內容,看一下有沒有明顯的錯誤。

看似一切都 OK 的話,就可以把這個內容,手動貼到 WordPress 產生一篇新的文章了。
WordPress 自動發文
當我們掌握了怎麼自動翻譯後,接下來就可以讓 WordPress 自動化的發文了。WordPress 有一套 CLI 的程式可以來讀取文章列表和內容的工具,但這僅限於有主機的自架 wordpress。若你是使用一些無 CLI 的 wordpress 的話,可能就不適用,但你仍然可以透過翻譯後,再由 web 貼上的方式來進行。
WP CLI
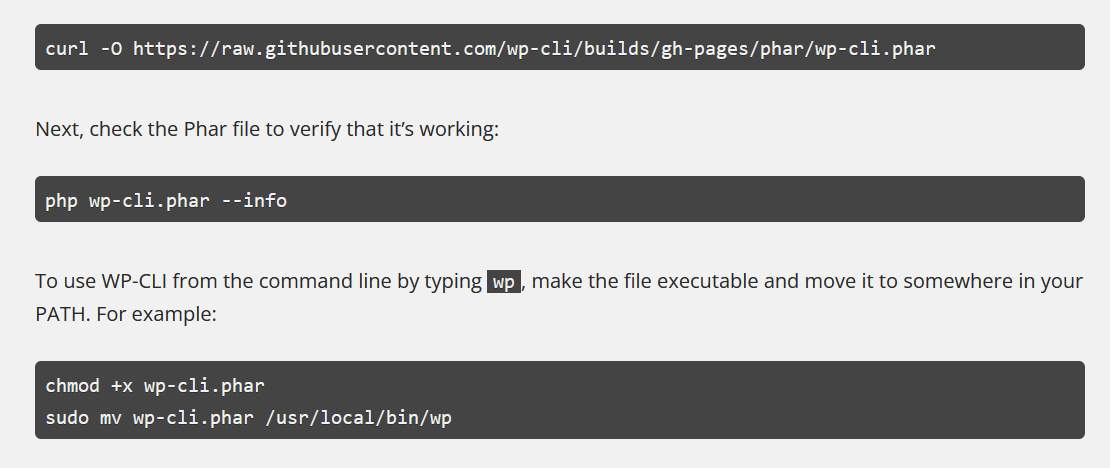
WordPress 的 CLI 安裝方式如下,其實也就是把檔案抓下來,放到 /bin 下面而已。
WP CLI Remote
很明顯的,Wordpress 的主機和 AI 主機大多數狀況下是不同台,所以我們需要從遠端去取得 WordPress 的資料進行翻譯。這方面 WordPress 的官網也有說明,簡單的說就是建一個 ~/.wp-cli/config.yml 檔案,裡面填上主機的名稱和帳號和網頁目錄。

前面的 @prod 就是這組帳號所代表的名稱、主機和位置,在下達 WP Cli 時就可以用 @prod 來代表它,其與主機的連線方式是使用 SSH。使用 GCP 來架 WordPress 的可以參考這篇文章,來實現免密碼的遠端登入。
自動翻譯發文
最後我實現的自動翻譯發文,是透過一個腳本,指定要翻譯 ID 就可以完成。這個腳本會先取得文章內容,再進行翻譯,過程中沒錯誤的話就進行發文。其中進行翻譯的腳本如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
!/bin/bash python ai_translate_new.py article.txt > all if [ $? -ne 0 ];then echo "#########################" echo "# AI Translate Error #" echo "#########################" exit 1 fi tidy -e all &> log cat log | grep "0 errors" &> /dev/null if [ $? -eq 0 ];then echo "#########################" echo "# Done #" echo "#########################" else echo "#########################" echo "# HTML Error #" echo "#########################" cat log | grep Error fi |
這其實就是呼叫 ai_translate_new.py 做翻譯,再呼叫 tidy 做個檢查。
做發文的腳本如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
#!/bin/bash POST_ID=$1 if [ "$POST_ID" = "" ];then echo "請提供要翻譯的文章 ID" exit 1 fi #wp @prod post list --fields=ID,post_title > all TITLE=`wp @prod post get $POST_ID --field=post_title` if [ $? -ne 0 ];then echo "讀取 $POST_ID 標題失敗" exit 1 fi wp @prod post get $POST_ID --field=post_content > article.txt dos2unix article.txt if [ $? -ne 0 ];then echo "讀取 $POST_ID 內容失敗" exit 1 fi echo "#### 翻譯標題 ####" sleep 1 ENG_TITLE=`python small_translate.py "$TITLE"` if [ $? -ne 0 ];then echo "翻譯成英文標題失敗" exit 1 fi echo "#### 開始翻譯內容 ####" sleep 1 ./translate.sh if [ $? -ne 0 ];then echo "翻譯內容失敗" exit 1 fi scp -i ~/.ssh/id_rsa all XXXXX@moon-half.info:/home/XXXXX/public_html/remote_post if [ $? -ne 0 ];then echo "複制檔案到遠端失敗" exit 1 fi NEW_ID=`wp @prod post create ./remote_post/all --post_title="$ENG_TITLE"` if [ $? -eq 0 ];then echo "發文成功. 文章 ID $NEW_ID" exit 0 else echo "發文失敗" exit 1 fi |
這部份主要是利用 WP CLI 的取得文章標題、內容、發文的功能來做自動化,在每一個步驟中都考慮失敗的狀況,來反饋給使用者。文章是先透過 scp 到遠端,再透過指定檔案來發文。CLI其實也可以在參數指定內容來發文,不過一篇文章幾千字,應該是不太適合。
自動翻譯小技巧
為了讓 AI 翻譯更加準確,應該儘量簡化使用到的格式。像目前的 wordpress,就只用到 pre, h3~h5, ui, ol 等幾個 tag。也許目前的 AI 翻譯還不是很完美,但透過一些小技巧,還是可以讓它為你工作的。
結語
透過開源的 AI 大語言模型,的確可以節省了很多時間,也不用依賴要錢的服務,但所需的知識的確不少。我一直覺得用戶要掌握一定的CLI技術能力,這樣才能把科技玩轉與手掌之間。若只能透過別人的 API 或 GUI,反而是 LP 被捏在別人手裡。API 說變就變、GUI 沒有自動化能力,那這些能力就是你不能掌握的。
有人說「AI 不會取代你,取代你的是會用 AI 的人」,希望大家可以掌握更靈活應用這些大模型的技能。
本文的 AI 協助翻譯已發表於此。


{kind=link}