Current large language models all have accompanying HTTP APIs, such as the one mentioned in this article. Using it is not complicated, but the parameters required to use it seem to be a bit excessive. In fact, building your own LLM API involves receiving a POST or GET request on an HTTP server, and then returning the response obtained from the LLM’s chat API to the HTTP server.
This self-built approach feels more customizable to some extent, of course it is also very likely that I am not familiar with the official API.
To customize this service, it’s actually just necessary to add Python HTTP functionality to a general CLI example. Here’s an example using Qwen, which records my own code.
LLM API program
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
# -*- coding: utf-8 -*- import os import sys import time from transformers import AutoModelForCausalLM, AutoTokenizer from transformers.generation import GenerationConfig from http.server import BaseHTTPRequestHandler, HTTPServer import logging from urllib.parse import unquote DEFAULT_CKPT_PATH = 'Qwen-14B-Chat-Int4' from opencc import OpenCC s2t = OpenCC('s2t') t2s = OpenCC('t2s') seed=0 class S(BaseHTTPRequestHandler): def _set_response(self): self.send_response(200) self.send_header('Content-type', 'text/plain; charset=utf-8') self.end_headers() def do_GET(self): self._set_response() i = self.path.find("?q=") if i == -1: logging.info("No GET content") self.wfile.write("Use '/?q=' to ask question".encode('utf-8')) else: url = self.path[i+3:] url = unquote(url) logging.info(url) q = t2s.convert(url) r = ask(q, config) r = s2t.convert(r) self.wfile.write(r.encode('utf-8')) def do_POST(self): content_length = int(self.headers['Content-Length']) # <--- Gets the size of data post_data = self.rfile.read(content_length) # <--- Gets the data itself logging.info("POST request,\nPath: %s\nHeaders:\n%s\n\nBody:\n%s\n", str(self.path), str(self.headers), post_data.decode('utf-8')) self._set_response() post = post_data.decode('utf-8') post = t2s.convert(post) r = ask(post,config); r = s2t.convert(r) self.wfile.write(r.encode('utf-8')) def run(server_class=HTTPServer, handler_class=S, port=8080): logging.basicConfig(level=logging.INFO) server_address = ('', port) httpd = server_class(server_address, handler_class) logging.info('Starting httpd... http://0.0.0.0:' + str(port)+'\n') logging.info('example: http://127.0.0.1:8080/?q=who is Trump') try: httpd.serve_forever() except KeyboardInterrupt: pass httpd.server_close() logging.info('Stopping httpd...\n') def load_model_tokenizer(): tokenizer = AutoTokenizer.from_pretrained( DEFAULT_CKPT_PATH, trust_remote_code=True, resume_download=True, ) device_map = "auto" model = AutoModelForCausalLM.from_pretrained( DEFAULT_CKPT_PATH, device_map=device_map, trust_remote_code=True, resume_download=True, ).eval() config = GenerationConfig.from_pretrained( DEFAULT_CKPT_PATH, trust_remote_code=True, resume_download=True, ) return model, tokenizer, config def ask(query, config): history = [] response, history = model.chat(tokenizer, query, history=history, generation_config=config, past_key_values=None) return response model, tokenizer, config = load_model_tokenizer() run() |
Language model-related functions.
- load_model_tokenizer(), ask(): load_model_tokenizer() loads the model, ask() gets the prompt responses from the LLM.
Functions related to HTTP:
- class S, run(): The former is the base class for an HTTP server, which handles GET and POST requests. The latter is the method to start the service.
Save the above code and after starting it, you can connect on port 8080.
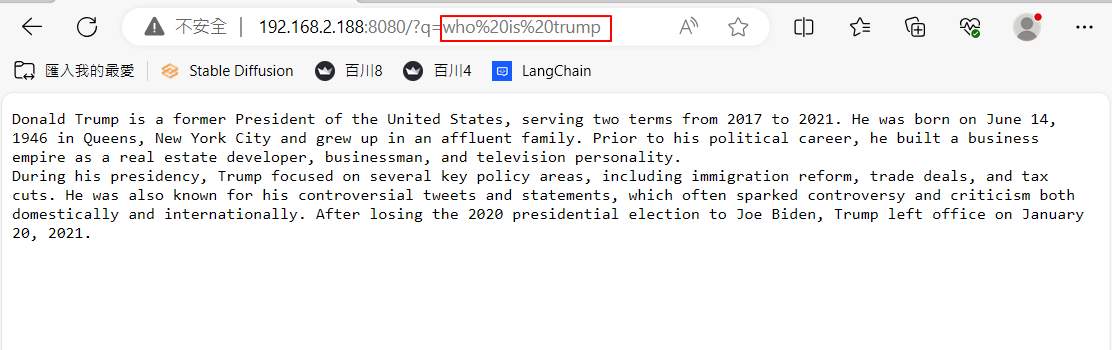
Using the GET method, just append “/?q=” followed by the question to the end of the browser URL. The following is the answer to “who is Trump,” with the %20 inserted by the browser itself.
To use POST, you can accomplish simple tasks by using a shell script with curl.
|
1 2 3 4 |
#!/bin/bash Q="$1" curl -d "$Q" -H "Content-Type: application/x-www-form-urlencoded" -X POST http://localhost:8080/ echo "" |

Conclusion
The advantage of building your own API is that you can customize some keywords to achieve special functions, such as starting or stopping the history feature, or instantly grabbing network data. Although it’s not very smart, it is indeed more practical.

{kind=link}