前幾篇有一個介紹 人聲分離的文章,其實也是在學習聲音克隆中所要用到的工具。
So-Vits-Svc是「SoftVC VITS Singing Voice Conversion」的縮寫,其原始來自於 VITS (一篇TTS論文的實作)。So-Vits-Svc 是專門用來克隆唱歌聲音,因為我只會用,就不做太多說明了。主要是網路資源比較多,就試用了這個專案。
所謂的「資源比較多」就是youtube上的介紹比較多,普遍是大陸打包的Windows整合包。雖然對 Linux 上幫助比較少,但其內部已經幫忙收集好所需的模型,也是幫了不少忙。so-vits-svc github 介紹的所需模型比較亂,有這個整合包裡的東西就夠了。
我參看過的 Youtube 影片,這邊列一下,讓有需要的人也可以參考一下。
訓練辦法
Youtube 裡面的解說是直接用自己的聲音來訓練,所以要先講個半小時錄音。這樣有點小浪費時間,我的做法先去 youtube 找2個書藉解說的影片,時長個30分鐘,太短就多找幾部合併。然後將第一個影片的聲音取出去做訓練,完成後套用在第2個影片的聲音上。這種方式可以比較結省時間。
Youtube 影片的聲音取出,可以直接使用之前文章介紹過的 yout 網站。要合併幾個音檔,則用 ffmpeg 命令
|
1 |
ffmpeg -i "concat:a1.mp3|a2.mp3|a3.mp3" -c copy a4.mp3 |
音檔是 mp3 或 wav 都沒關係。影片儘量要選沒音樂的,或者再透過UVR做過去背景音樂。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 2 |
conda create -n vits python=3.8 conda activate vits |
下載 so-vits-svc 與安裝套件 (失敗)
|
1 2 3 4 |
git clone https://github.com/svc-develop-team/so-vits-svc cd so-vits-svc pip install -r requirements.txt echo "conda activate vits" > env |
由於官網的 WEBUI 太簡略,用起來不太能用。接下來,請以此整合版(從網路上抓的)來進行操作,也許有一天官網的 WEBUI 更友善再使用。
so-vits-svc 模型下載
根據官網與比較網友整合包,比較之後只要下載2個模型
- vec768l12 encoder: ContentVec, checkpoint_best_legacy_500.pt
- Pre-trained NSF-HIFIGAN Vocoder: nsf_hifigan_20221211.zip
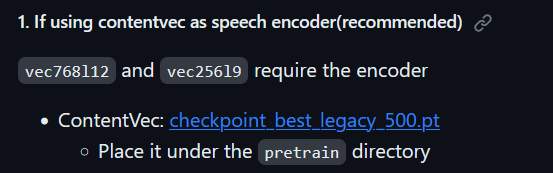
encoder下載
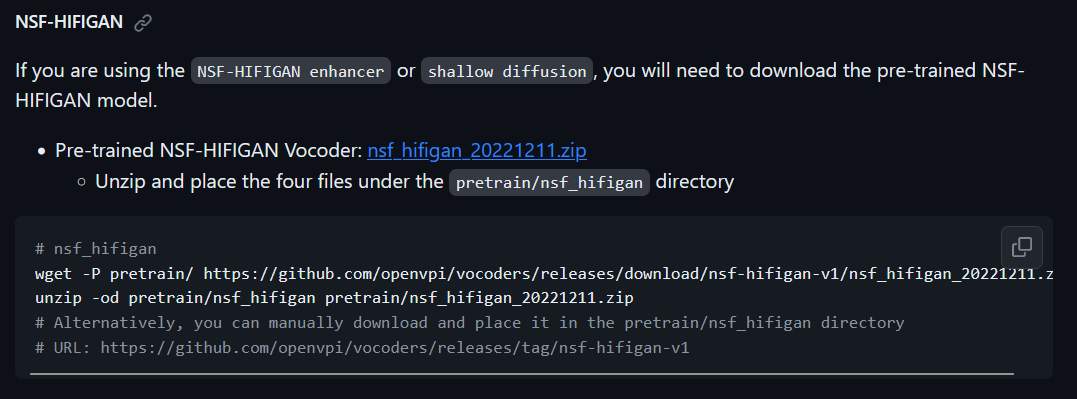
HIFHGAN 下載
下載後, vec768l12 放在 pretrain目錄下. NFS-HIFIGAN 則解壓縮放在 pretrain 下。其目錄結構如下.
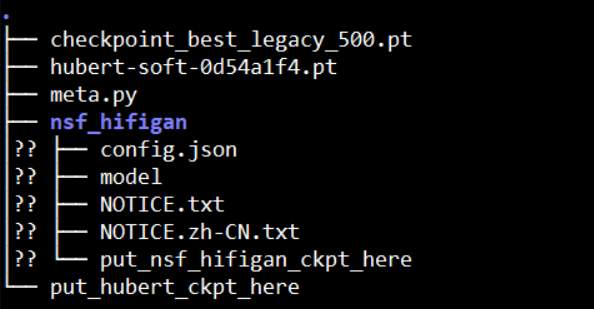
預訓練模型檔案
下載audio-slicer音檔切片工具
|
1 2 3 |
git clone https://github.com/openvpi/audio-slicer cd audio-slicer pip install -r requirements.txt |
聲音在給 so-vits-svc處理前,要先切片並去除靜音片段。用法如下
|
1 |
python slicer2.py 聲音檔 --out wav |
此命令就會將聲音檔切片,並將片段放入目錄 wav/ 中。
然後我們將 wav 目錄移到 so-vits-svc/dataset_raw 下面, 以便稍後處理。
訓練前的預處理
進入 so-vits-svc 執行下面幾個命令來做預處理
|
1 2 3 4 |
python resample.py python preprocess_flist_config.py --speech_encoder vec768l12 python preprocess_hubert_f0.py --f0_predictor crepe --use_diff python cluster/train_cluster.py #訓練類聚模型 |
在第3步時,有時會錯誤,好像是因為預訓練的 model 與 cuda 版本不合. 可以參照錯誤訊息來更新 pytorch 版本. 下面的命令是更新到 11.8. 若沒有錯誤的話,則不需執行其它動作。
|
1 |
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 |
開始訓練
最後執行下面命令來開始訓練
|
1 |
python train.py -c configs/config.json -m 44k |
中途若要停止訓練的話,直接中斷即可,下次執行此命令就會繼續。若要整個全部重新,將 logs/44k/ 下面的檔案都砍掉再重新執行。網路上的影片說訓練半天就有不錯的效果,不過這當然是隨你的顯卡有關。我用 RTX 4090 大概要訓練到 10000 個 steps 才覺得比較好,大概也是需要24小時的時間。
由於其訓練過程中的 GPU 使用率並非一直滿載,感覺還有優化的空間。訓練的參數是存在 configs/config.json 下的
- epochs: 總訓練次數,到達就不會再訓練了。如果你覺得不夠好,可以加大此數值
- eval_interval: 多少 steps 要儲存一次模型。
啟動 WEB Server
執行下列命令,就可以在 port 7860 進行服務了。
|
1 |
python app.py |
進行推論
打開瀏覽器後,可以看到主畫面
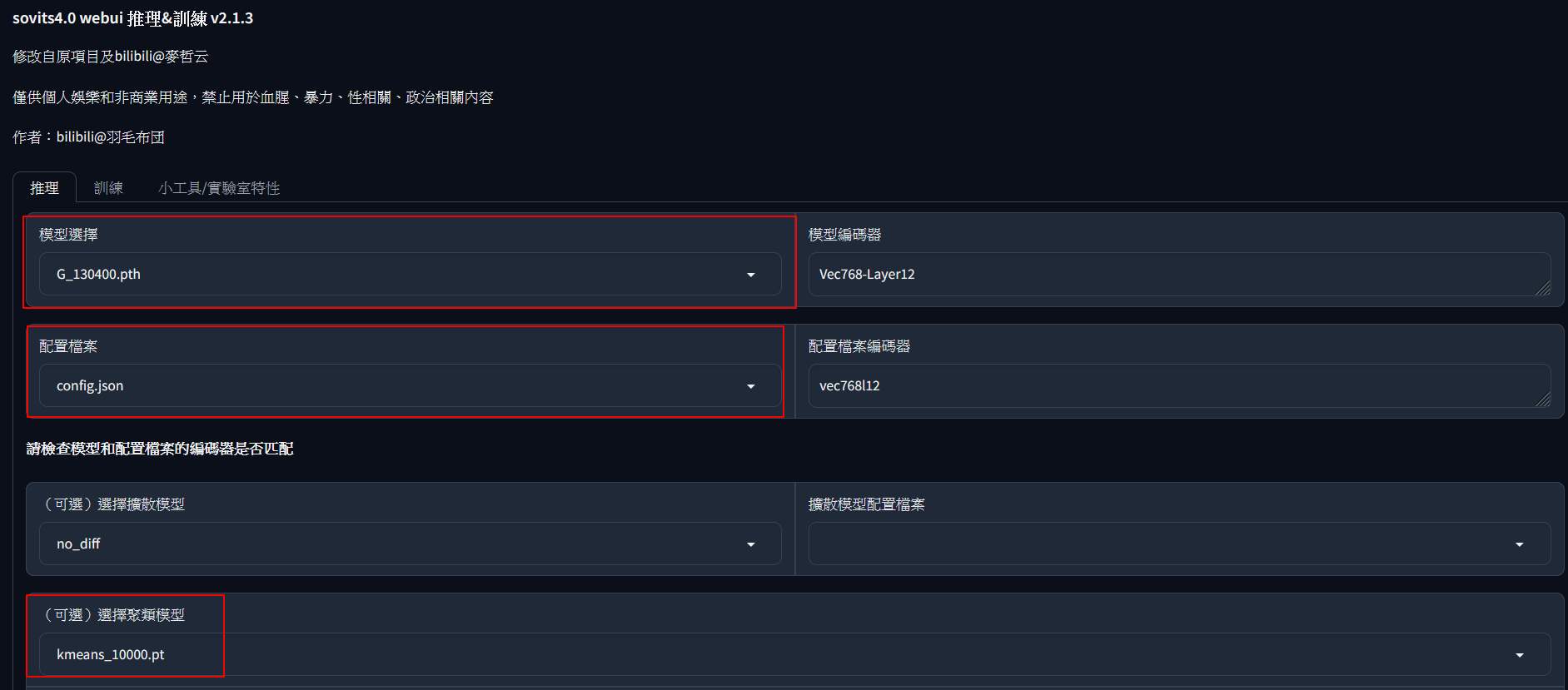
模型選擇最新的,配置檔案應該只有一個,聚類模型也是只有一個。
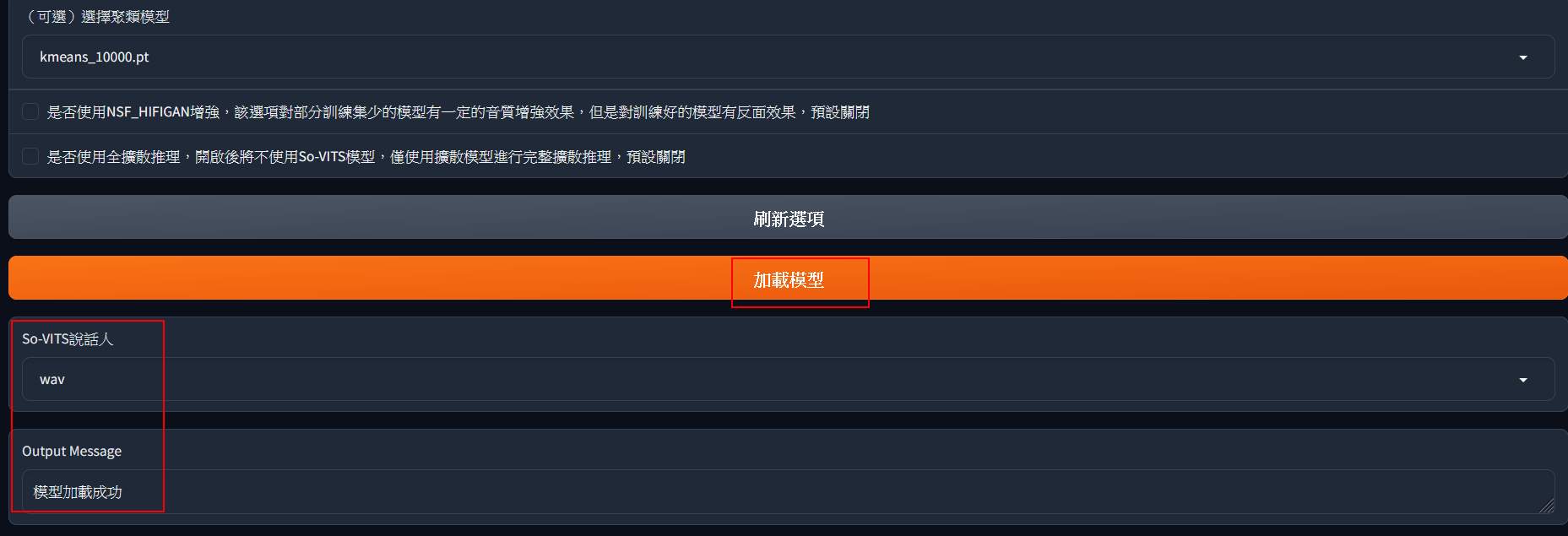
往下捲動,就可以看到加載模型。
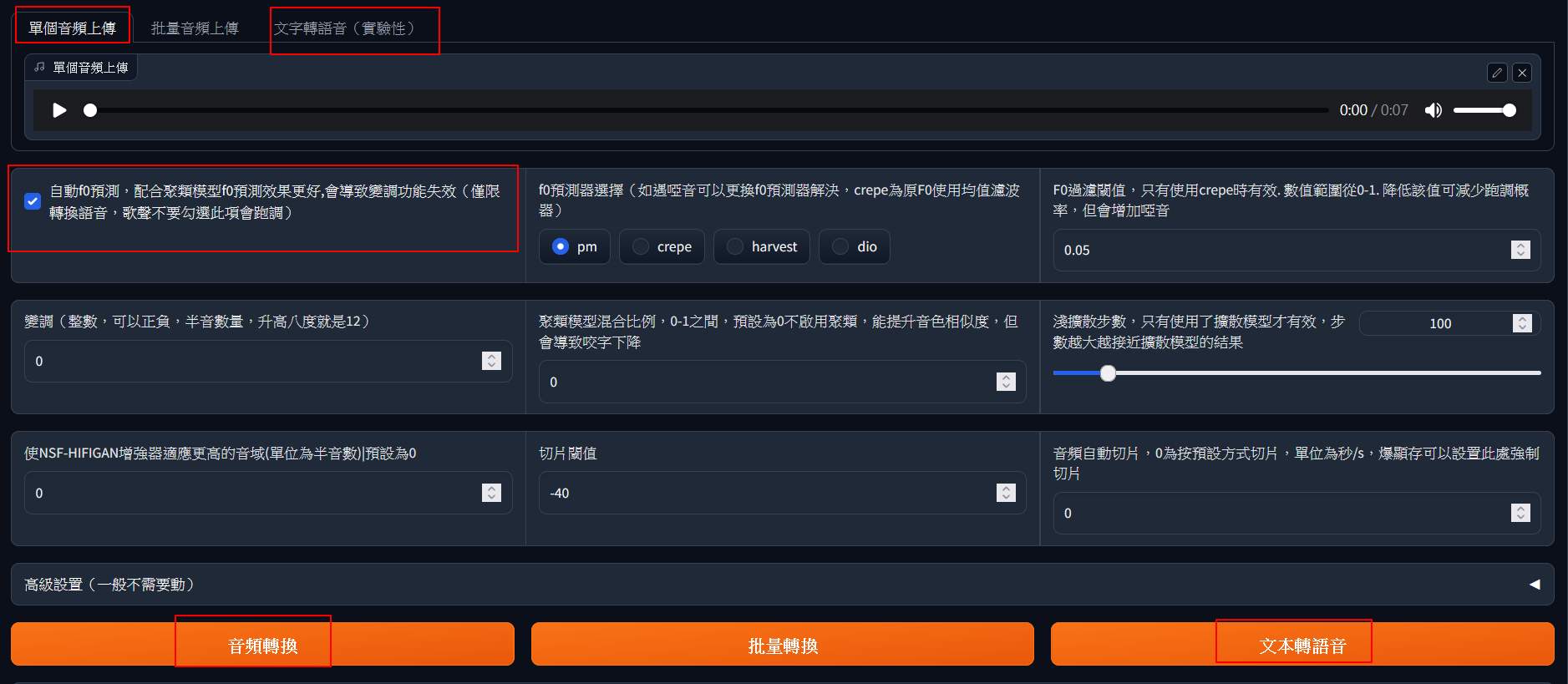
載入模型後,就可以用檔案上傳來進行克隆或直接用文字TTS後再轉換。這邊要特別勾選的是「自動f0預測」,如不是轉換唱歌的,就要勾選,不然會出現電音。
結語
如同其它 AI 模型一樣,聲音克隆也是在發展之中,UI 的部份還是非常起步。相信以後穩定後,會持續有所進步。


{kind=link}