最近看到一個人聲替換的 Youtube 影片,雖然替換效果不太好,但人聲分離效果還不錯,就記下來了。由於這是一個有 GUI 的程式,暫時還無法在 docker 裡成功運行 vnc,所以就先記下來了。
關於在 nvidia docker 裡要運行 GPU 加速的分離,經過了多次的試驗,發現使用 nvcr.io/nvidia/pytorch 22.12-py3 是可以的,若是 23.08-py3 則不行,其它的版本沒試過。而 docker 裡面還要裝桌面環境和 VNC server, 會在後面說明。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 2 |
conda create -n uvr python=3.8 conda activate uvr |
UVR – Ultimate Vocal Remover
UVR 專案提供了去人聲的功能,這也是本篇主要要描述的部份。
安裝下面套件。
|
1 2 3 4 5 |
git clone https://github.com/Anjok07/ultimatevocalremovergui cd ultimatevocalremovergui # 把 requirements.txt 裡的 DORA 套件移除 pip3 install -r requirements.txt echo "conda activate uvr" > env.sh |
啟動 UVR 與模型下載
進入 GUI 環境,並啟動 UVR 程式
|
1 |
python UVR.py |
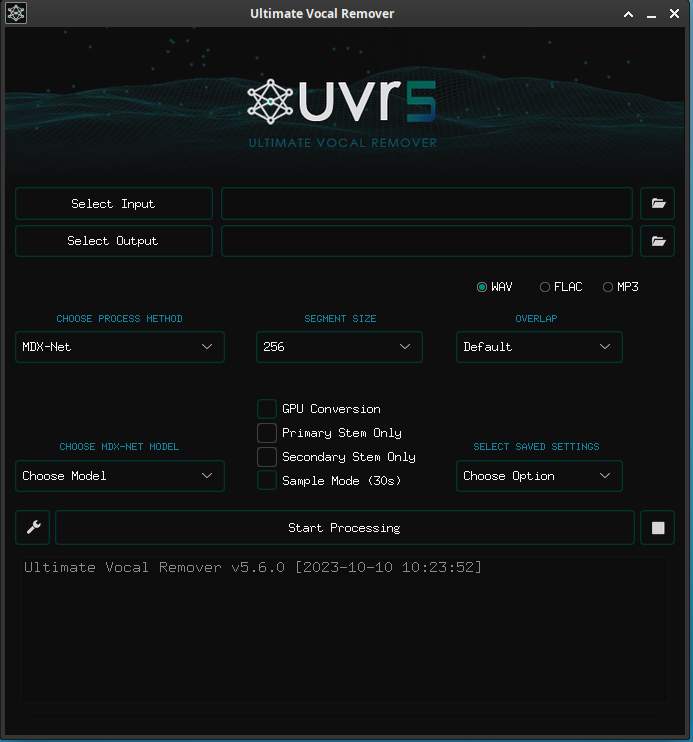
點擊 「Start Processing」左邊的 ICON ,以進行模型下載。
首先下載 VR 模型
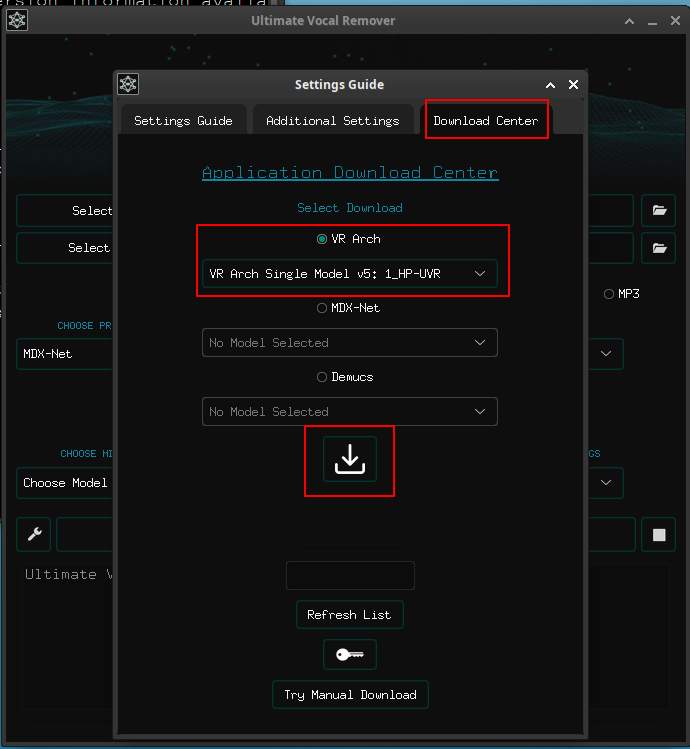
接著下載 Demusc 模型
人聲分離
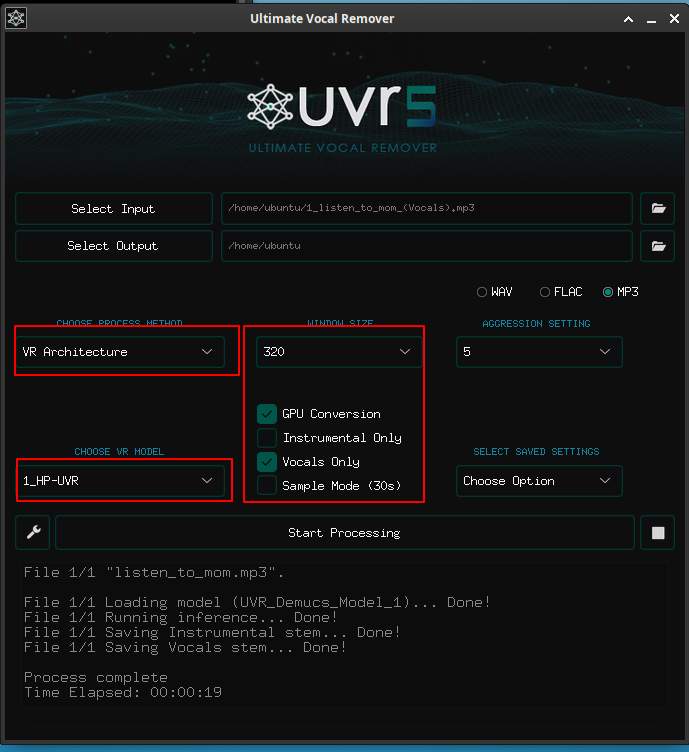
接著回到主畫面,選擇要分離的音樂檔,與選擇模型
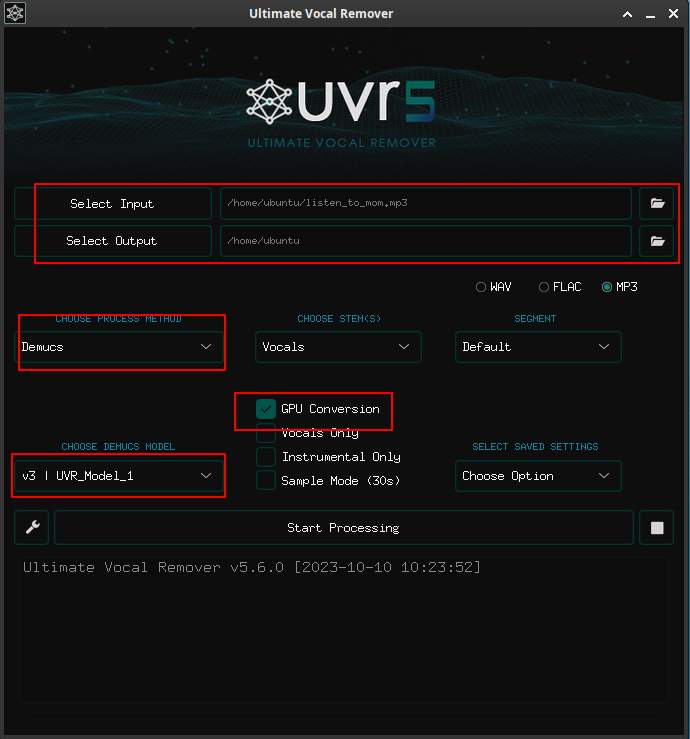
這邊選擇輸入的檔案,與輸出的目錄。選擇模型 DEMUCS,方法是 UVR_MODEL_1,開啟 GPU 加速,接著就可以開始進行人聲分離。分離會產生2個檔案,一個是樂器的檔案,一個是人聲的。

進一步分離
接著要將人聲的部份,再去除一些迴音。使用下面畫面的模型和方法
Docker 內的安裝
以下是在 nvidia docker image 「nvcr.io/nvidia/pytorch:22.12-py3」內的環境建置流程,安裝步驟同上。這邊要注意的是 vnc 要使用 tigervnc-standalone-server,使用 tightvnc 的話會因為不支援 xrandr 而無法啟動 UVR。
|
1 2 3 4 5 6 |
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -it -p 5901:5901 nvcr.io/nvidia/pytorch:22.12-py3 sed -i "s/archive/tw.archive/g" /etc/apt/sources.list apt-get update apt-get install xfce4 xfce4-goodies xorg dbus-x11 x11-xserver-utils tigervnc-standalone-server net-tools vim firefox sudo python3-tk mkdir ~/.vnc vim ~/.vnc/xstartup |
在 ~/.vnc/xstartup 輸入以下內容
|
1 2 3 4 5 6 7 8 |
#!/bin/sh unset SESSION_MANAGER unset DBUS_SESSION_BUS_ADDRESS startxfce4 & [ -x /etc/vnc/xstartup ] && exec /etc/vnc/xstartup [ -r $HOME/.Xresources ] && xrdb $HOME/.Xresources xsetroot -solid grey |
然後下達下以命令來啟動 VNC Server
|
1 2 |
chmod a+x ~/.vnc/xstartup vncserver :1 -localhost no |
結語
這是人聲替換流程中的前置部份,先將人聲分離,由於人聲替換的部份效果不是很好,可能就不會再特別說明。

{kind=link}