在上一篇AI 學習紀錄 – 單步GPT推論 (2)實現在單步推論後,要回頭過來講訓練的過程。之前的文章沒細看其訓練的過程,所以在這就先從字典產生來看。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 |
conda create -n vocab python=3.9 |
建立專案目錄
使用下面的命令,將專案下載(如附件)下來,並建立環境切換檔。
|
1 2 3 4 5 |
cd projects mkdir vocab cd vocab echo "conda activate vocab" > env.sh source ./env.sh |
安裝套件
安裝下列所需套件
|
1 |
pip install keras thulac tqdm tensorflow |
程式碼
產生字典檔案程式如下,是從 GPT2-Chinese 專案參考過來的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
import argparse import thulac from tqdm import tqdm from keras.preprocessing.text import Tokenizer def main(): parser = argparse.ArgumentParser() parser.add_argument('--raw_data_path', default='train.json', type=str, required=False, help='原始訓練語料') parser.add_argument('--vocab_file', default='vocab.txt', type=str, required=False, help='生成vocab連結') parser.add_argument('--vocab_size', default=50000, type=int, required=False, help='詞表大小') args = parser.parse_args() lac = thulac.thulac(seg_only=True) tokenizer = Tokenizer(num_words=args.vocab_size) print('args:\n' + args.__repr__()) print('This script is extremely slow especially for large corpus. Take a break.') f = open(args.raw_data_path, 'r') lines = f.readlines() for i, line in enumerate(tqdm(lines)): lines[i] = lac.cut(line, text=True) tokenizer.fit_on_texts(lines) vocab = list(tokenizer.index_word.values()) pre = ['[SEP]', '[CLS]', '[MASK]', '[PAD]', '[UNK]'] vocab = pre + vocab with open(args.vocab_file, 'w') as f: for word in vocab[:args.vocab_size + 5]: f.write(word + '\n') if __name__ == "__main__": main() |
這個程式的用法是指定產生字典的來源檔 (–raw_data_path)、字典的儲存位置 (–vocab_file)與最大的字詞限制(–vocab_size)。
程式裡面首是利用 thulac 這個中文斷詞工具,來取得一句話中的字詞的。另外一個有名的工具是結巴(jieab),應該也是相似的功能。斷詞後,就會將這些詞丟入 tokenizer 斷詞器進行處理儲存,做一些統計排序儲存類的操作。最後再將結果寫到字典檔內就完成了。
L15~16: 分別初始化了斷詞器(thulac)與 tokenizer (分詞器)
L20~24: 來源檔的內容被一次讀了進來,讓後逐行丟進斷詞器內,並將斷詞結果放進 list。原本參考的程式是使用 json 格式來處理,這樣前處理會比較麻煩,與是我將json的部份捨器了,就是一行一行的做。
L25~26: 將斷詞好的內容,一次全部丟進 tokenizer 內處理。並將結果放入 vocab list。
L27~31: 將結果寫入輸出檔。在結果的最前面,會放入5個預置的內容,'[SEP]’, ‘[CLS]’, ‘[MASK]’, ‘[PAD]’, ‘[UNK]’。這個我不是很確定,但應該是 tokenizer 幾個預定的單元,以在實際使用時來表達一些狀況。[UNK] 是字詞不認得,若在模型實際使用時,提供了tokenizer不認得的內容做轉換,就會轉出[UNK]的ID與內容。其它的可能是換行或補字之類的。
最後實際的部份輸出如下
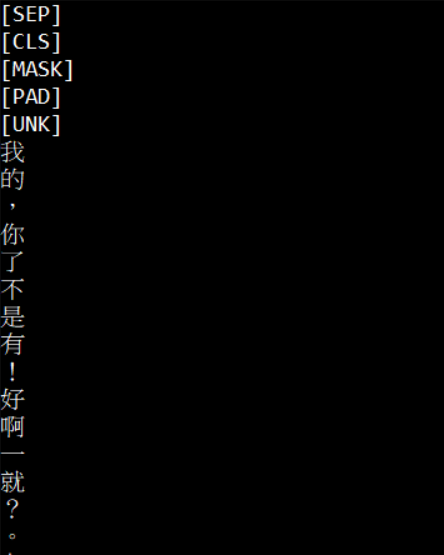
結語
寫文章主要還是梳理自己的知識,感覺清晰多了 XD


){kind=link}