一陣子沒投入大語言模型,就會發現有一些驚奇。倒也不是有多大的進步,很是佈屬上有了很大的便利性。所謂的佈屬大語言模型,其實是有點浪費時間的,因為還處於起步階段,很多步驟都還是用手動設定的,所以很多事情都還很麻煩。
終於,到了一個比較成熟的時間了,雖然還有待改進,但也是方便許多。今天要講的就是這Ollama與 Openwebui 的組合。
Ollama
Ollama 可以說是提供了一個統一的介面,來進行大模型的推論、 上傳與管理,使得以往要自行針對每個模型的客制化語法不用再關心,而且其也提供了相容的大語言模型下載,都給你處理的妥妥當當的。使用 Ollama 就著重於這個 API 就好了,而不必在分心於 LLM 用法的事務。但 Ollama 在執行時,並沒有 UI 介面可檢示,僅有 API可使用。
ollama 還是提供了簡易的 cli 指命可以來下載各個大語言模型,可以利用 CLI 進行問答的部份,當然用起來就沒那麼順手。
另外 Ollama 在使用的大模型時,會自動判別資源是否充足,而使用 GPU 或 CPU,所以可以避免記憶體不足的情況,這點對於平常使用時非常有幫助。以往常常碰到的 OOM 只能重啟模型,就不太會碰到了。
Openwebui
Openwebui 簡單的說,就是提供一個類似 ChatGPT 的介面,來進行與大語言模型的問答。而其 API 的接口,就是與 Ollama 搭配的,所以這2個可以說要一併使用,也相得益彰。
安裝
ollama 需要使用管理員權限,而 openwebui 建議使用 docker 運行,官網也沒解釋要怎麼手動來安裝。這也是目前比較簡單的運行方式,目前先以 Windows 為目標來進行。
安裝 Ollama
安裝 Ollama, 在其官網下載進行安裝即可。但由於其在模型下載時,會於預設位置安裝,比較難管理,建議可設定環境變數來指定其下載位置。
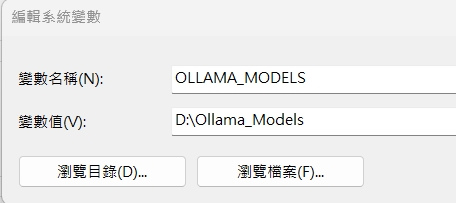
安裝完 ollama 後,可以透過 cli 管理模型,進行其它模型下載或刪去。

安裝 openwebiui
安裝 openwebui 需要使用 Desktop Docker, 安裝完 docker 後, 依其官網所示, 用下列命令下載 docker image
|
1 |
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main |
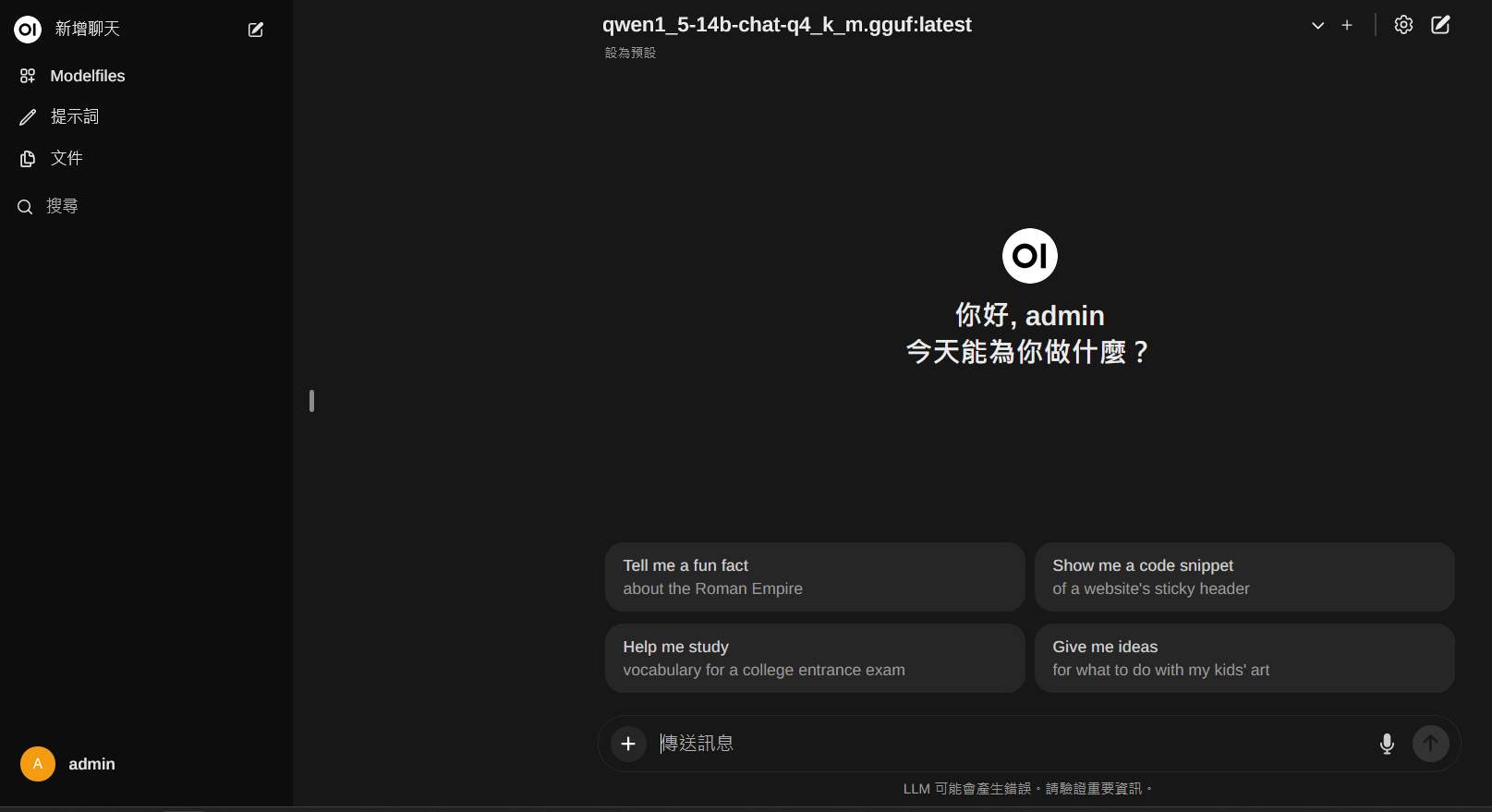
安裝完後,就可以瀏覽 http://127.0.0.1:3000 來進行登入。第一次需進行註冊,首位註冊者就是管理員,email 隨便填即可。登入後畫面如下
下載模型
openwebui 終究只是一個前端的 UI, 模型的下載還是要由 Ollama 所認知。
方法1: 由 ollama cli
從 admin –> setting –>模型, 從 ollama.com 下載模型。可以在其網頁上瀏覽可用的模型,最後會有下載的指令,如下
|
1 |
ollama run llama3:8b-text-q4_K_S |
在dos命令裡下載即可
方法2: 由 openwebiui 上傳
此方法不建議。
方法3: 模型轉移
要把 Ollama 下載的模型轉移到另一台的話,可以使用命令
|
1 |
ollama show mistral:7b --modelfile |
會出現類似的回報,也是所謂的 modelfile。把下面的內容存起來,複製 FROM 後面指的檔案,再移到其它機器進行匯入。而此處 FROM 的檔案當然也要改到適當位置和名稱。
|
1 2 3 4 5 6 7 8 |
# Modelfile generated by "ollama show" # To build a new Modelfile based on this one, replace the FROM line with: # FROM mistral:7b FROM /usr/share/ollama/.ollama/models/blobs/sha256-e8a35b5937a5e6d5c35d1f2a15f161e07eefe5e5bb0a3cdd42998ee79b057730 TEMPLATE """[INST] {{ .System }} {{ .Prompt }} [/INST]""" PARAMETER stop "[INST]" PARAMETER stop "[/INST]" |
匯入時下達以下命令, 就可以了。
|
1 |
ollama create myllm -f modelfile.txt |
對話
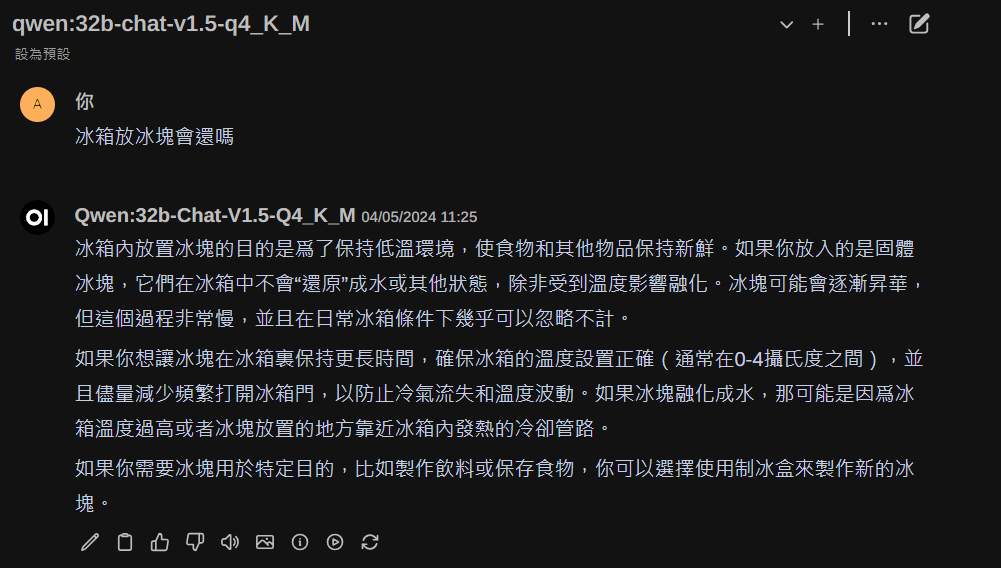
當完成這一些後,建議可以做一個重啟, ollama 會自動啟動,openwebui 也會自動啟動。此時瀏覽 http://127.0.0.1:3000後就可以進到對話的頁面了。
Openwebiui 優化
由於 LLM 一直是一種很吃vram的東西,所以在載入模型時有些參數的調整,對於速度就會有大的影響。要進行設定請以openwebui 的管理員進行設定,也就是第一個註冊的用戶。從左下角的用戶名稱點入後,按下設定。
減少前後文 TOKEN 數
常用 –> 進階參數
- 上下文長度: 768
- 最大 Token 數: 384
- 保持活躍: -1
由於上下文長度和 Token 數會影響 VRAM 的使用量,當VRAM不足時就會變成CPU來連算導致回應緩慢. 另外, Ollama 在一個 LLM 一陣子不使用後會自動將其卸載,這樣會導致要使用時要再等待一段時間,所以此處將其改為 -1 ,就不會卸載了。
不要自動標題
介面 –> WebUI 擴充參數 –> 自動生成標題. 由於自動生成標題會導致其載入另一個LLM來產生標題,導致反應很慢,此處建議關掉此功能。
Windows 上安裝 HWiNFO
由於 Ollama 都會偷偷卸載模型,所以觀察 GPU 和 VRAM 的使用率就很重要。從 Linux 上的話,可以使用 nvtop 來觀察。從 Windows 上的話,就可以利用 HWiINFO 這到工具來辦到。


{kind=link}