人臉識別算是一套很成熟的技術了,早在很久以前的 Google Picassa 相簿就可以做的不錯。但真的想用的時候,才發現網路上找不到一套 Linux 下可以
- 辨識臉部
- 標識面孔
- 支援 CLI
- 要輕量,有人推荐 KDE 的相簿軟體,感覺這很不好客製化,也沒學到技術。
於是就開始自己找起來了,過程還算順利,畢竟是比較成熟的技術了。辨識準確率相信還有很多可以微調的方面,本篇就只介紹我自己用的淺顯易用的方式,做為技術儲備。
人臉WEBCAM識別專案
本篇的內容都是從這個文章衍生出來的,作者也把程式碼放在了 github 上了。原作者原本是要用 GPU 來做影象辨識的,所以若下載直接執行,會非常慢可以說是動不了。如果有人想先直接試試看的,就把程式碼中的 “cnn” 改成 “hog”。另外有一個 bug, 把倒數第2行的”video_capture” 改成 “video”.
接下來的部份,會先說明如何用 GPU 來做人臉辨識。如果沒興趣的可以跳過,把有cnn的部份改成hog,用CPU來執行。
基本環境安裝
一些基本的環境 (如 anaconda、共用 script) 的設定,已經寫在【共同操作】 這篇文章裡,請先看一下,確保所以指令可以正確運作。
建立 conda env
由於每個專案的相依性都不同,這裡會為每個案子都建立環境。
|
1 2 3 4 |
conda create -n vits python=3.8 conda activate opencv pip install face_recognition pip install opencv-python-rolling |
這邊安裝的是 opencv-python-rolling, 應該是開發版的樣子。由於發文當下 opencv-python 還是使用 opencv 4.x 版,無法簡單支援中文印字。所以這邊用 opencv-python-rolling 是 opencv 5.x 的,比較方便使用中文。
重新編譯 DLIB 以支援 CUDA
OpenCV 會使用到 dlib,而預設從 pip 安裝的 dlib 是不支援 GPU 的,需要重新編譯。而要重新編譯,就要先安裝編譯工具 cmake 與 vs-builttools 與 Nvidia cuDNN。
- cmake 請在這裡下載
- 而 buildtools 則要到微軟的網站下載,此處我們下載 vs2019 「Build Tools for Visual Studio 2019」的版本,下載需要微軟的帳戶。
- cuDNN 也是要註冊下載,根據自己的 CUDA 版本下載相對應的檔案。打開後,把檔案解壓到 C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.2 (以 CUDA 12.2 為例).
- 可以參考這裡
編譯 DLIB
直接上指令
|
1 2 3 4 5 6 7 8 9 |
git clone https://github.com/davisking/dlib.git pip uninstall dlib cd dlib mkdir build cd build cmake .. -DDLIB_USE_CUDA=1 -DUSE_AVX_INSTRUCTIONS=1 cmake --build . cd .. python setup.py install --set DLIB_USE_CUDA=1 |
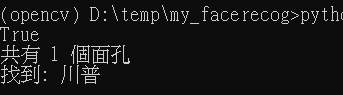
編譯完後,用下面的指令來測試是否已支援 dlib 的 GPU
|
1 2 3 4 |
import os os.add_dll_directory(os.path.join(os.environ['CUDA_PATH'], 'bin')) import dlib dlib.DLIB_USE_CUDA |
有支援的話就會顯示 True. 上面有一行 os.add_dll_directory() ,是不需要的,但這次試就要加,不然會碰到什麼dll加載失敗的問題。有可能跟 python 的版本相關。
下載我寫好的專案
基於前面提到的專案, 做了一些修改可以用 web 來標記人臉與方便處理照片. 首先下載安裝套件
|
1 2 3 |
git clone https://gitlab.com/eagleein578/my_facerecog.git cd my_facerecog pip install -r requirements.txt |
專案裡面有放了一張美國前總統川普的照片,以做為運行範例。檔案是在 img/unhandled
尋找不認識的臉
|
1 |
python extract_unknown_face.py |
這個指令會把 img/unhandled 下的照片,做人臉識別,如果有不認識的臉,就會把臉部截下來,放到 img/unknown_faces 目錄下。處理過的照片會被移到 img/handled.
標記不認識的臉
臉部標記的部份,會尋找 img/unknown_faces 下的檔案來做標記,標記完後會被移到 「img/known_faces/臉的名字」 目錄下.
|
1 |
streamlit run tag_face.py --server.headless true |
此時會執行一個 web server, 打開瀏覽器 http://127.0.0.1:8501
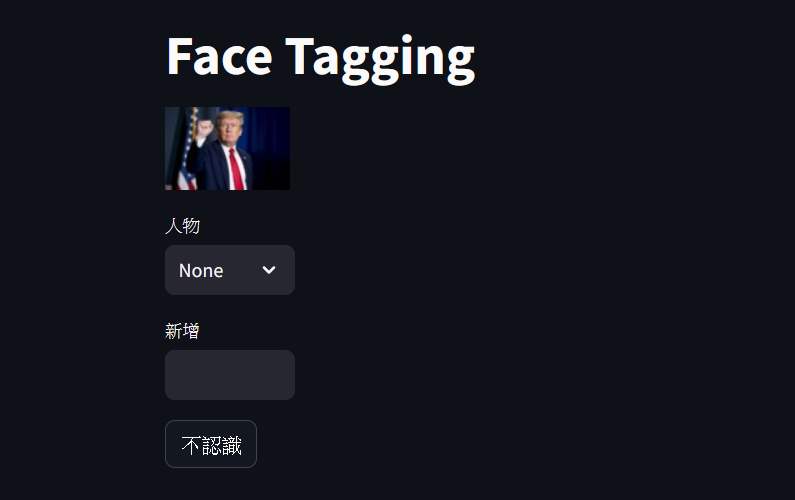
標記網頁
這邊有3個選項可以選
- 人物: 已經辨識過的人物,可以直接選。選了後就會直接標記,不需再確定
- 新增: 可以新增人物的名字,建立新的標記. 打完就按 Enter 確定
- 不認識: 不認識的就直接按鈕就好. 臉會被移到 img/known_faces/junk 下面
尋找認識的臉
|
1 |
python list_face.py img/handled/71efab46a60de0859084b4b083c989a9.jpg |
用 list_face.py 來尋找指定檔案是否有認識的人. 這個腳本會載入 img/known_faces 下所有認識的臉,來做搜尋
用 Camera 做即時識別
用下面命令來啟動 webcam 做即時識別
|
1 |
python camera_face_recognize.py |
程式會載入識別過的臉來顯示。
使用 GPU
範例程式碼預設是使用 hog 模型來做辨識的,用 GPU 的話則是用 cnn 模型。預設選 hog 是怕沒裝正確的dlib而使用cnn,會整個卡住。若要改成使用 GPU 的話,把下面三個檔案的 MODEL 改成 cnn 即可
- camera_face_recognize.py
- extract_unknown_face.py
- list_face.py
GPU 主要在 camera 的部份會很有感,變順很多。至於準確率我也沒大量比較過,不確定。
調整辨識容忍度
當在搜尋認識的臉時,會有一個容忍度值可以調,範圍在 0~1。越低代表比較嚴格,越高就比較寬鬆 (容易認錯),這個要多識識看,才能知道誤判率。
修改程式內的 TOLERANCE 的值,一樣是改上面那3個檔案,不需要設成一樣. 例如可以找陌生臉(extract_unknown_face.py)的時候比較寬鬆, 在找認識臉的時候比較嚴格(list_face.py)
改善速度
每次在載入認識的臉都是直接從圖檔重算,這可能比較花時間,由其在圖多了之後。其特徵(face_encodings)應該是可以存檔直接載入,不過這我還沒有研究,有需要加速的人可以從這方面著手。
結語
研究這個人臉辨識也學到蠻多的,順便學了一下 streamlit 做網頁,的確比以往的前後台方式方便。人臉識別的應用很多,功能做的太齊也很多難,主要是把基本要素學起來,以後要組合也容易了。


{kind=link}