近一年來玩的 AI 模型常常要下載很大的Python套件,若反覆下載是很浪費時間的。之前的做法是將所有使用者的 .cache 目錄共用,這樣可以減少下載的時間。另外一個做法就是像以往 http proxy 的做法,就是在中間放一個代理程式,下載過的東西就會被存下來。後面如要再下載,就可以不必從源頭抓了。
第2種方式應該是比較正式的做法,也方便可以移到公司內來運用。因為公司內網是不能上網,所以用 Python 時,若套件都要一個個抓是很麻煩的。用這種方式就可先在外網建立一個 proxy server,先透過這個 server 安裝所需套件。在把 proxy server 移到內網,就可以有齊全的套件了。
失敗嘗試 bandersnatch
問 gpt 或 google, 會有推荐使用 bandersnatch 這個套件的,它可以把整個server都mirror下來,跑起來的確也是有模有樣,的確下載了非常多套件,佔用了快 2TB 。我只下載部份的平台 (aarch64, linux, cp37),並沒有對套件名稱做過濾,但就是怎樣都缺必要套件。
像是 gradio, streamlit, numpy, requests 之類很常用的東西也沒有,感覺總是不齊,缺東缺西。嘗試了好幾次後,就放棄了。
devpi server
這邊我們要用的是 devpi 這個套件。它包含了 server 和 client 的程式,可能是比較複雜的應用。我這裡只使用單純的 server 功能而已,參考的文章是這一篇,並沒有權限控管或上傳的需要。
首先安裝下列套件並初始化
|
1 2 |
pip install devpi-server devpi-init |
接著啟始服務器,
如果要只使用本地套件而不連到外網的話,要加上 “–offline-mode” 的參數。
|
1 |
devpi-server --host=0.0.0.0 & |
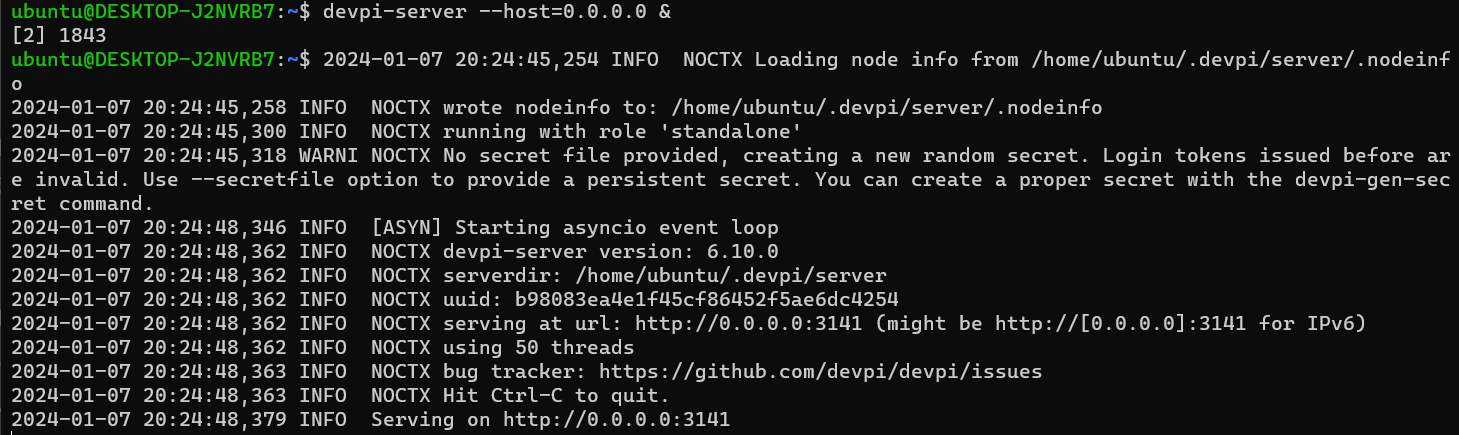
啟動服務器後,它會自動去 pypi.org 抓所有的套件列表,這時打開 http://127.0.0.1:3141/root/pypi/+simple/ 應該可以看到一個很長的文檔,這樣就算有正常啟動了。因為這檔案有 25 萬行左右,所以一直打不開也沒關係。
接著就可以使用 pip 透過這個 server 來安裝套件。
|
1 |
pip install --index-url http://127.0.0.1:3141/root/pypi/+simple numpy |
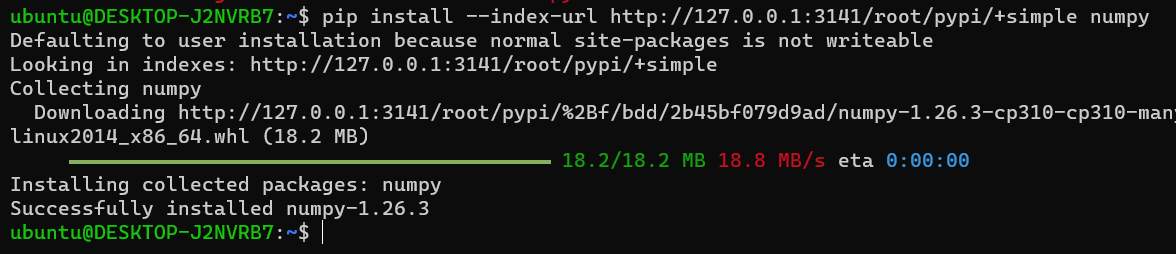
被 proxy 保留的檔案,會放在 “~/.devpi/server/+files/” 的目錄下,當需要轉移整個 proxy 內容時,只要將 ~/.devpi 打包,再轉移到其它機器上的相應位置就可以了。

該下載的版本
由於 python 的套件包會分 OS (windows, linux, macos), 硬體架構 (x86_64, aarch64) 和 python 版本 (3.6,3.7..3.10) 之類的。所以在需求端(內網)如果有指定的要求,在外網下載時就要使用的版本,會乾脆一點都都抓都行。建議的方法是先把所需要的套件都列出來,然後分別用不同的平台和不同的 python 版本來下載。
不同的OS/硬體
Windows / Linux 在一般x86上可用virtualbox或vmware虛擬機來完成。aarch64 的話,就要使用 qemu 來進行,可以參考我這些文章。
不同的Python版本
要切換不同的 python 版本,最方便的還是使用 anaconda 或 miniconda 。在 windows/linux/aarch64 上都可以使用。
結語
就算不是在公司內網用python, 若你有在試各種 AI 模型, 可能就值得裝一個 pypi 的 proxy。常常切換不同的 pytorch 環境,就會需要常常下載了。



{kind=link}