隨著人工智慧技術的不斷發展,語音辨識的應用變得越來越廣泛。在這篇文章中,我將示範如何使用 OpenAI 提供的 API,快速實現語音轉文字的功能。本文的程式碼範例基於 Python 語言,並使用 Op
在這篇文章中,我們將介紹如何利用 OpenAI 的 DALL·E 圖像生成 API,實現文字轉圖像的功能。文生圖指的是通過輸入一段文字描述(Prompt),生成與之相符的圖像。以下將結合程式碼實例,詳
OpenAI 的大型語言模型(如 GPT-4)提供強大的自然語言處理能力,能幫助解決多種問題。本文將介紹如何在 Python 中使用 OpenAI 的 API,並對範例程式碼進行詳盡的解說。 前置準備
之前有一篇討論如何用 Enigma Virtualbox 來將 QT 打包成單一執行檔,以進行佈署的文章。但用這個方法在 Windows 上進行的話,會需要很多手動的步驟,有點麻煩。 雖然印象中好像有
之前對於 docker 和 lxc (linux container) 都有一點模糊,隨著這次在 ARM64 上架設 docker 環境,有點瞭解到其實它們都是利用 Linux Kernel 提供的
在定這個文章標題的時候,我也是很困惑。我另外也想定成 pytorch 模型轉成 gguf,總之就是要轉成可以量化的模型。gguf 檔應該是由 meta 所制定的,因為需要由 llama.cpp 這個專
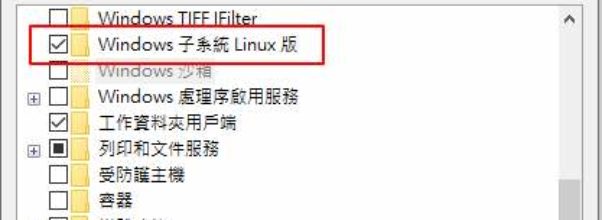
自從 Windows WSL (Windows Subsystem for Linux) 功能上線以來,對於我這個 Linux 工作者來說,方便性真的增加了很多。以往有很多自動化或Linux才有的CL
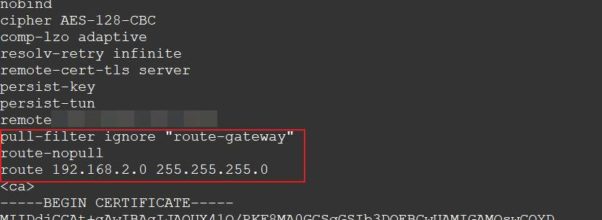
由於自己家裡架了一個 OpenVPN Server, 以方便我連回去做一些測試。但 Router 預設是會把資料都透過這條VPN送出去,這對我而言並不是很需要。如果是自己架的 VPN Server 想
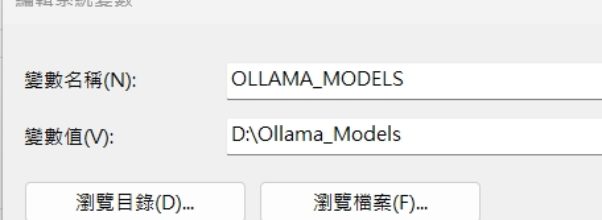
一陣子沒投入大語言模型,就會發現有一些驚奇。倒也不是有多大的進步,很是佈屬上有了很大的便利性。所謂的佈屬大語言模型,其實是有點浪費時間的,因為還處於起步階段,很多步驟都還是用手動設定的,所以很多事情都
現在已經是 2024/02/08 了,已經是小年夜了。今年比較晚寫年度回顧,因為不忍直視…..雖然其它還算順利,但還是喝了一整年,對於自己很弱的腦波感到很困擾。 2022的年度回顧在此。今